
 网络分析能力修行模型
网络分析能力修行模型
作者:易隐者 发布于:2012-11-14 20:53 Wednesday 分类:网络分析
概述
数次应业内朋友之邀,为其团队培训网络分析技术,从第一次开始,我就着手架构这个能力修行模型的框架,但还不够完善和成熟。随着我对网络分析技术理解的深入和本身水平的提升以及培训次数的增加,我不断的将其完善,并最终形成现在的雏形。
根据这个网络分析能力修行模型,初学者可以清晰了解如何入手学习网络分析技术,并按部就班、循序渐进的提升网络分析技术的能力水平。
所谓“道可顿悟,术需渐修”,但愿此文能够成为诸位网络分析初学者“悟道”的法门。
网络运行的本质
网络运行的本质是什么?是数据报文与协议。

数据报文是网络运行世界里,具有完整信息的、最小的组成单元,而协议则是数据报文在网络内交互必须遵循的规则。因此掌握了这两者,基本上就可以把握网络运行的本质。
网络分析技术将数据报文和协议完美的结合起来,因此网络分析技术通常也被叫做协议分析、数据包分析或报文分析。那么网络分析到底是如何工作的呢?
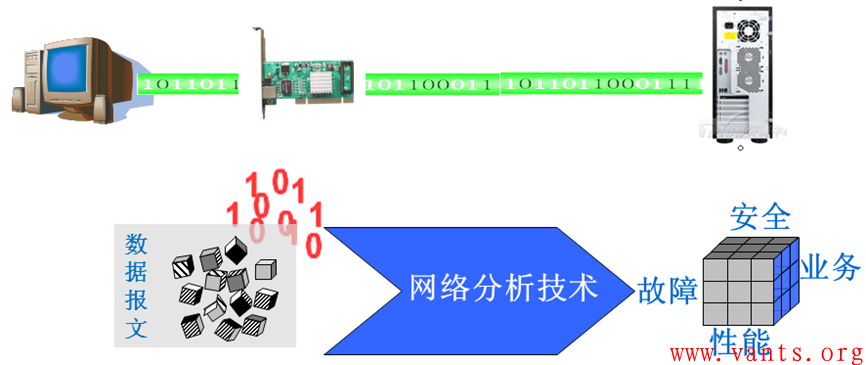
网络分析技术是通过捕获网络通讯过程中的数据包(数据包是网络通讯过程中有意义的、最小的组成单元),并通过对捕获到的数据包进行深入的统计和分析,从而洞穿网络各个层面(包括性能、安全、业务以及故障等)运行情况的一种技术。
通过网络分析技术,我们可以轻松透视网络运行的本质,如果我们的网络分析技术能力非常强,我们的技术水平会远远超出那些只精通于具体设备的工程师们,成为名副其实的网络层面的专家,那么我们如何修行才能提升自己的网络分析技术呢?下面我将通过网络分析能力修行模型展开详细介绍。
网络分析能力修行模型
我将自己的成长经验总结为下图所示的网络分析能力修行模型:
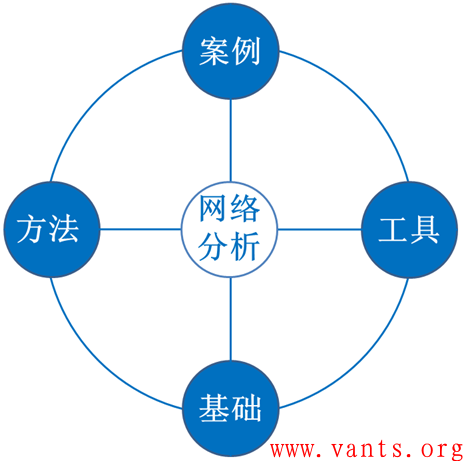
在这个模型中,围绕网络分析能力的提升,主要包含以下四方面的内容:
基础
古语云“千里之行始于足下”、“万丈高楼平地起”。做任何事情都离不开基础,网络分析技术能力的提升同样需要牢固扎实的技术基础作为支撑。
工具
古语云“巧妇难为无米之炊”。工具可以帮助我们事半功倍,大大提高我们的工作效率,没有称手的工具,纵然你有一身本领,却难免陷入纷繁复杂的二进制世界难以自拔。
方法
古语云“砍柴不照纹,累死砍柴人”。有基础有工具却不得法,虽可解决一些常见问题,但往往是随性而起,难以为继。即使大部分情况下你能成功解决问题,也只能说明你的运气和感觉都还不错,但是你无法将你的运气和感觉传递给你的团队、学生及他人。简言之:无章法,不足道。
案例
古语云“纸上得来终觉浅,绝知此事要躬行”。基础牢靠、精通工具、掌握方法,这已经为我们践行网络分析技术做好充分的准备,我们需要在实际工作环境中,把握任何机会,践行自己的网络分析技能,在利用网络分析技术解决问题之后,不断总结,并形成文档;另外一条践行的捷径是讨论学习他人的案例,将他人的经历经验借鉴过来为己所用,在短时间内快速提升自己。总之,多践行,多总结,多学习。
根据这个网络分析能力修行模型,我将网络分析技术的学习和提升分为四个阶段,如下图所示:
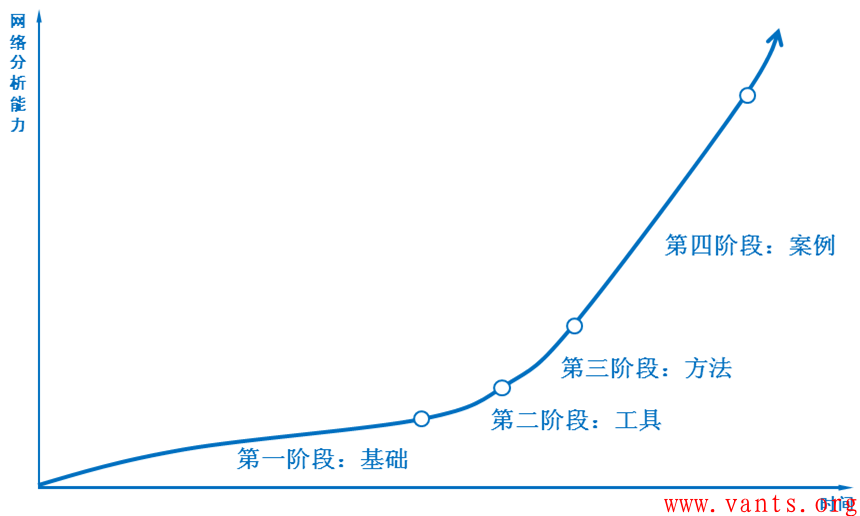
第一阶段:打好基础
这个阶段较为漫长,并且会一直持续伴随整个学习成长的过程。一般而言,这个阶段主要是学习网络基础、各种网络和安全设备的工作原理和机制、不同系统或设备的报文处理流程、TCP/IP协议体系、各常见应用等。在这个阶段,大部分是通过自主学习来获得提升的。
第二阶段:熟悉工具
在扎实的技术基础上,熟练掌握1-2种网络分析的工具,不会花费太多的时间,但是如想成为高手,必须充分理解各种常见工具的优势特点,学会在不同的情况下,选择性的综合利用这些工具的优势特性,提高我们解决问题的效率。
第三阶段:掌握方法
掌握网络分析的常规思路,深入理解网络分析方法的原理和使用场景,能够在实际工作环境下,按照网络分析方法和思路展开网络分析工作。
第四阶段:践行案例
综合利用已学知识和掌握的方法,不断通过实际案例践行网络分析技术,以及对他人案例的学习,让自己的网络分析技术得以快速提升和升华。
这四个阶段在大的学习和提升方向上是线序的,但这并不是绝对的,比如我们既可以借助他人的案例加固基础知识,又可以在实际案例中提升工具使用的熟练度,也可以利用网络分析工具学习协议体系……
网络分析能力修行模型不同阶段的学习资料
在我的个人博客蚂蚁网——www.vants.org中,基本涵盖了网络分析能力修行模型中各个阶段学习的内容,下面我将各个阶段的资料做一个统一整理,方便初学者学习参考。
网络分析基础
防火墙的状态检测 http://www.vants.org/?post=24
应用层检测/深度包检测(DPI)http://www.vants.org/?post=23
TCP异常终止(reset报文)http://www.vants.org/?post=22
TCP重传 http://www.vants.org/?post=36
ICMP重组超时 http://www.vants.org/?post=35
TCP SACK选项 http://www.vants.org/?post=74
传输层的响应时间(系统层响应时间/服务器响应时间)http://www.vants.org/?post=115
关于防火墙的arp代理功能对不同格式的arp报文的处理情况的实验 http://www.vants.org/?post=121
ARP代理(Proxy ARP)http://www.vants.org/?post=119
免费ARP(gratuitousARP)http://www.vants.org/?post=118
ARP表的更新和老化http://www.vants.org/?post=120
第三方延时http://www.vants.org/?post=117
应用响应时间(ART)http://www.vants.org/?post=116
ICMP通讯管理性过滤禁止差错报文(type 3,code 13)http://www.vants.org/?post=127
连接数相关知识http://www.vants.org/?post=126
TCP/IP 应用程序的通信连接模式http://www.vants.org/?post=182
TCP保活(TCP keepalive)http://www.vants.org/?post=162
多次RST以及不同场景下的RST报文的差异http://www.vants.org/?post=141
端系统对RST报文的过滤http://www.vants.org/?post=140
经受时延的确认(Delay ACK)http://www.vants.org/?post=114
TCP MSS与PMTUD http://www.vants.org/?post=109
IP分片(IP Fragment) http://www.vants.org/?post=106
TCP 的PUSH标志位http://www.vants.org/?post=102
TCP交互式应用http://www.vants.org/?post=101
基于UDP的应用如何保证应用数据的可靠性http://www.vants.org/?post=99
关于“client push”应用响应时间测量方法的讨论http://www.vants.org/?post=30
iPhone与Multicast DNS http://www.vants.org/?post=130
非标准TCP三次握手建立连接过程一例http://www.vants.org/?post=91
ACK flood攻击的影响http://www.vants.org/?post=136
基于UDP组播实施分片攻击的可能性http://www.vants.org/?post=98
关于防火墙访问控制的疑问http://www.vants.org/?post=26
TCP/IP 数据包处理路径 http://www.vants.org/?post=188
网络分析工具
常见网络分析工具特色功能简介及其在实际工作中的应用之缘起 http://www.vants.org/?post=43
常见网络分析工具特色功能简介及其在实际工作中的应用之Network Monitor http://www.vants.org/?post=41
常见网络分析工具特色功能简介及其在实际工作中的应用之Omnipeek http://www.vants.org/?post=66
Wireshark对ping报文的解码显示(BE与LE)http://www.vants.org/?post=133
利用科来与IDS Informer构建网络攻击学习平台http://www.vants.org/?post=31
网络分析方法
疑难故障分析常规流程和思路http://www.vants.org/?post=27
疑难网络故障的分析方法和原理之对比分析法http://www.vants.org/?post=49
疑难网络故障的分析方法和原理之关联分析法http://www.vants.org/?post=51
如何跟踪分析数据经过中间设备后的变化以及这些变化给客户端与服务器带来的影响http://www.vants.org/?post=93
一切皆有可能http://www.vants.org/?post=122
异常流量分析方法——发现-定位-管控http://www.vants.org/?post=185
如何保证中间设备两端捕获的数据包的时间同步性?http://www.vants.org/?post=50
网络分析案例
视频点播服务间歇性中断故障分析案例http://www.vants.org/?post=73
访问搜狐163时主页变为2008年某日主页面故障分析案例http://www.vants.org/?post=89
某学院专网网站打开慢故障分析案例http://www.vants.org/?post=92
FTP登陆故障分析http://www.vants.org/?post=103
某单位经过CA认证的业务应用访问缓慢故障分析案例http://www.vants.org/?post=104
网页打开慢但HTTP下载快故障分析案例http://www.vants.org/?post=128
某业务系统由于连接数限制导致间歇性访问慢故障分析案例http://www.vants.org/?post=125
数据包中出现超长帧的分析http://www.vants.org/?post=184
关于vista系统机器无法通过防火墙上网的故障分析解决案例http://www.vants.org/?post=124
关于服务器端发送FIN报文之前的数秒等待时间行为的分析http://www.vants.org/?post=95
大包传输丢包故障http://www.vants.org/?post=34
两台soho级小路由之间的“正义”之战http://www.vants.org/?post=163
某加密机经天融信防火墙后应用异常故障案例http://www.vants.org/?post=107
负载均衡故障诊断:一个MSS值引发的疑案http://www.vants.org/?post=110
关于网内抓包出现0.33.216.220IP地址问题的分析http://www.vants.org/?post=88
F5负载均衡环境下某应用故障分析案例http://www.vants.org/?post=65
某地税网上申报业务系统故障分析报告http://www.vants.org/?post=58
高新区房产局房产管理业务故障分析解决报告http://www.vants.org/?post=32
某部队部分网段访问总部网站故障分析案例http://www.vants.org/?post=25
IPS在线升级故障分析案例http://www.vants.org/?post=16
使用Omnipeek分析SSH端口攻击案例http://www.vants.org/?post=134
针对随机组播地址的ping攻击案例http://www.vants.org/?post=132
基于UDP 7000端口的DOS攻击案例http://www.vants.org/?post=131
基于UDP 80端口的DOS攻击案例http://www.vants.org/?post=113
可能的数据库密码猜解行为http://www.vants.org/?post=84
PHP漏洞扫描—morfeus fucking scanner http://www.vants.org/?post=67
web站点cookie安全问题一例http://www.vants.org/?post=64
标签: 同步 状态检测 TCP异常终止 团队 IDS Informer 网络分析 数据包分析 协议分析 网络分析能力修行模型
SharkFest'20 Virtual Retrospective
作者:易隐者 发布于:2020-11-5 9:57 Thursday 分类:网络分析
THURSDAY SESSIONS
- 01: BACNet and Wireshark for Beginners by Werner Fischer
- 02: Going down the retransmission hole by Sake Blok
- 03: IPv6 security assessment tools (aka IPv6 hacking tools) by Graham Bloice
- 04: Improving packet capture in the DPDK by Stephen Hemminger
- 05: Kismet and Wireless Security 101 by Mike Kershaw
- 06: Packets! Wait... What? A very improvised last-minute Wireshark talk about things you can find in pcap files that are funny, interesting or weird. I don't know. Let's find out together by Jasper Bongertz
- 07: TLS encryption and decryption: What every IT engineer should know about TLS by Ross Bagurdes
- 08: Why an Enterprise Visibility Platform is critical for effective Packet Analysis? by Keval Shah
- 09: Troubleshooting Cloud Network Outages by Chris Hull
- 10: TCP SACK overview & impact on performance (subject to change) by John Pittle
- 11: Automation TIPS & tricks Using Wireshark/tshark in Windows by Megumi Takeshita
- 12: How Long is a Packet? And Does it Really Matter? by Stephen Donnelly
FRIDAY SESSIONS
- 13: Make the bytes speak to you by Roland Knall
- 14: USB Analysis 101 by Tomasz Moń
- 15: TLS decryption examples by Peter Wu
- 16: The Packet Doctors are in! Packet trace examinations with the experts by Drs. Blok, Greer Landström, Rogers
- 17: Analyzing Honeypot Traffic by Tom Peterson
- 18: Intrusion Analysis and Threat Hunting with Suricata by Josh Stroschein and Jack Mott
- 19: The Other Protocols (used in LTE) by Mark Stout
- 20: Practical Signature Development for Open Source IDS by Jason Williams and Jack Mott
- 21: Ostinato - craft packets, generate traffic by Srivats P
- 22: Introduction to WAN Optimization by John Pittle
- 23: Solving Real World Case Studies by Kary Rogers
- 24: Analyzing 802.11 Powersave Mechanisms with Wireshark by George Cragg
SharkFest'19 Retrospective
作者:易隐者 发布于:2020-11-5 9:39 Thursday 分类:网络分析
KEYNOTE PRESENTATIONS
Latest Wireshark Developments & Road Map
Gerald Combs
TUESDAY CLASSES
- 01: War story: troubleshooting issues on encrypted links by Christian Landström
- 02: TLS encryption & decryption: What every IT engineer should know about TLS by Ross Bagurdes
- Presentation Video (1:22:25)
- 03: Writing a Wireshark Dissector: 3 ways to eat bytes by Graham Bloice
- Presentation Video (1:18:07)
- 04: Solving (SharkFest) packet capture challenges with only tshark by Sake Blok
- Presentation Video (1:14:11)
- 05: How long is a packet? And does it really matter? by Stephen Donnelly
- Presentation Video (1:17:54)
- 06: Creating dissectors like a pro by generating dissectors by Richard Sharpe
- Presentation Video (1:20:38)
- 07: To Send or not to Send? How TCP congestion control algorithms work by Vladimir Gerasimov
- Presentation Video (1:30:56)
- 08: Taking a bite out of 100GB files by Betty DuBois
- Presentation Video (1:11:33)
- 09: Debugging TLS issues with Wireshark by Peter Wu
- Presentation Video (1:10:44)
- 10: IPv6 troubleshooting with Wireshark by Jeff Carrell
- 11: When TCP reassembly gets complicated by Tom Peterson
- Presentation Video (41:47)
- 12: Jumbo frames & how to catch them by Patrick Kinnison
- 13: Kismet & wireless security 101 by Mike Kershaw
- Presentation Video (1:20:16)
- 14: Tracing the untraceable with Wireshark: a view under the hood by Roland Knall
- Presentation Video (1:22:25)
- Presentation Video (1:18:07)
- Presentation Video (1:14:11)
- Presentation Video (1:17:54)
- Presentation Video (1:20:38)
- Presentation Video (1:30:56)
- Presentation Video (1:11:33)
- Presentation Video (1:10:44)
- Presentation Video (41:47)
- Presentation Video (1:20:16)
WEDNESDAY CLASSES
- 15: Automating cloud infrastructure for analysis of large network captures by Brad Palm & Brian Greunke
- Presentation Video (1:30:15)
- 16: My TCP ain't your TCP - ain't no TCP? by Simon Lindermann
- Presentation Video (1:26:14)
- 17: TLS1.3, DNS over HTTPs, DNS over TLS, QUIC, IPv6 PDM & more!by Nalini Elkins
- 18: Practical Tracewrangling: Exploring capture file manipulation/extraction by Jasper Bongertz
- Presentation Video (1:24:32)
- 19: TCP SACK overview & impact on performance by John Pittle
- Presentation Video (1:11:54)
- 20: IPv6 security assessment tools (aka IPv6 hacking tools) by Jeff Carrell
- Presentation Video (1:35:25)
- 21: Troubleshooting slow networks by Chris Greer
- Presentation Video(1:10:57)
- 22: Analyzing Windows malware traffic with Wireshark (Part 1) by Brad Duncan
- Presentation Video(1:10:57)
- 23: To send or not to send? How TCP congestion control algorithms work by Vladimir Gerasimov
- Presentation Video (1:30:56)
- 24: The packet doctors are in! Packet trace examinations with the experts by Drs. Blok, Bongertz, and Landström
- 25: Analyzing Windows malware traffic with Wireshark (Part 2) by Brad Duncan
- Presentation Video (1:04:26)
- 26: TLS encryption & decryption: what every IT engineer should know about TLS by Ross Bagurdes
- 27: Developer bytes lightning talks by Wireshark Core Developers
- 28: Wireshark visualization TIPS & tricks by Megumi Takeshita
- 29: Kismet & wireless security 101 by Mike Kershaw
- Presentation Video (1:20:16)
- Presentation Video (1:30:15)
- Presentation Video (1:26:14)
- Presentation Video (1:24:32)
- Presentation Video (1:11:54)
- Presentation Video (1:35:25)
- Presentation Video(1:10:57)
- Presentation Video(1:10:57)
- Presentation Video (1:30:56)
- Presentation Video (1:04:26)
- Presentation Video (1:20:16)
THURSDAY CLASSES
- 30: Using Wireshark to solve real problems for real people: step-by-step case studies in packet analysis by Kary Rogers
- Presentation Video (1:20:01)
- 31: TCP split brain: compare/contrast TCP effects on client & server with Wireshark (Part 1) by John Pittle
- Presentation Video (1:24:11)
- 32: Kismet & wireless security 101 by Mike Kershaw
- Presentation Video (1:20:16)
- 33: Capture file format deep dive by Jasper Bongertz
- Presentation Video (1:11:14)
- 34: TCP split brain: compare/contrast TCP effects on client & server with Wireshark (Part 2) by John Pittle
- Presentation Video (1:27:25)
- 35: Solving the impossible by Mike Canney
- Presentation Video (1:02:20)
- 36: A deep dive into LDAP: Everything you need to know to debug and troubleshoot LDAP packets by Betty DuBois
- 37: Wireshark visualization TIPS & tricks by Megumi Takeshita
- 38: Enrich your network visibility & analysis with Wireshark & ELK by Tajul Ariffin
- Presentation Video (1:05:55)
- 39: A walkthrough of the SharkFest Group & Individual Packet Challenges by Sake Blok, Christian Landström, and Jasper Bongertz
- Presentation Video (1:20:01)
- Presentation Video (1:24:11)
- Presentation Video (1:20:16)
- Presentation Video (1:11:14)
- Presentation Video (1:27:25)
- Presentation Video (1:02:20)
- Presentation Video (1:05:55)
三实“捕影”2018招人计划
作者:飞鸟 发布于:2018-1-26 13:45 Friday 分类:其 他
0x01 小组介绍
“捕影”应急响应小组是安徽三实公司旗下专门负责网络疑难故障处置、安全事件应急响应、业务系统性能优化、日志分析的团队。
1. 公安部一所网防G01安徽技术支撑团队;
2. 安徽省公安厅网安总队技术支撑团队;
3. 安徽唯一一支专注于网络疑难杂症与黑客攻击入侵应急响应的团队;
4. 协助政企金融用户处理数百起网络疑难故障;
5. 协助多地网安与用户处理数百起黑客入侵事件;
6. 在freebuf、团队博客蚂蚁网上发表了数百篇专业疑难故障与应急响应类文章;
7. 安徽省19大网络安全应急保障工作、组织几十家用户的应急演练;
8. 多次为安徽省公安厅、安徽省经信委、各地市公安/网信办提供技术培训和讲座;
9. 多位网络分析专家/应急服务专业级工程师/CISP/各种安全厂商认证工程师;
10. 团队博客www.vants.org、www.freebuf.com/author/feiniao。
0x03 招人计划
助理工程师
1. 熟悉常见网络结构
2. 了解基本的网络原理(交换机、路由器、防火墙等)
3. 掌握wireshark、科来等抓包软件的使用;能够在故障现场根据具体故障现象抓取相应的数据包;
4. 了解常见的网络设备、服务器、登录配置操作
5. 了解常见安全设备、存储设备、虚拟化的工作机制和原理,能够完成常规的操作;
6. 能与用户沟通,完成日常工作,并撰写报告;
7. 常规问题的分析和解决
8. 协助团队负责人完成其他常规工作。
技术工程师
1. 具备一定的安全能力,熟悉网络安全与web安全的原理
2. 了解常见攻击方式,如xss、sql注入、文件上传等原理
3. 熟悉主流安全设备的工作原理
4. 具有一定的分析和处理入侵事件的能力
5. 具备一定的日志分析能力,能够通过日志分析黑客攻击的痕迹
6. 熟悉TCP/IP协议,对数据包有一定的分析能力
7. 熟悉主流的网络设备,了解网络设备的工作原理
8. 能够独立处理日常的工作
9. 独立撰写用户服务过程文档。
(以上至少满足5条)
中高级安全工程师
1. 精通TCP/IP原理,具有独立解决用户网络疑难故障的能力
2. 深入理解应急响应的流程、具体步骤,可独立进行安全事件的应急处置
3. 了解IT项目管理知识体系,能够胜任公司大型安全服务项目经理;
4. 撰写体系化的技术文档并进行团队分享。
C开发工程师
1. 独立完成系统模块开发、维护,按计划完成各个模块日常开发工作;
2. 配合同事以及上级领导制定软件开发方案
3. 解决项目中因程序引起的故障问题;
4. 项目维护和新功能模块开发;
5. 良好的代码编写习惯、以及技术文档书写能力;
6. 良好的沟通与表达能力、思路清晰,较强的动手能力与逻辑分析能力。
0x04 联系方式
地址
合肥市高新区长江西路118号5F创业园A座408。
联系方式
Mail:liuqy@ahsss.com.cn
标签: 疑难故障 TCP wireshark 招聘 三实 应急响应 捕影 日志分析 招人 捕影小组 应急处置 三实捕影
省局门户网站地市信息公开栏目访问异常应急处置
作者:竹林再遇北极熊 发布于:2017-12-2 11:40 Saturday 分类:网络分析
1.1 拓扑结构
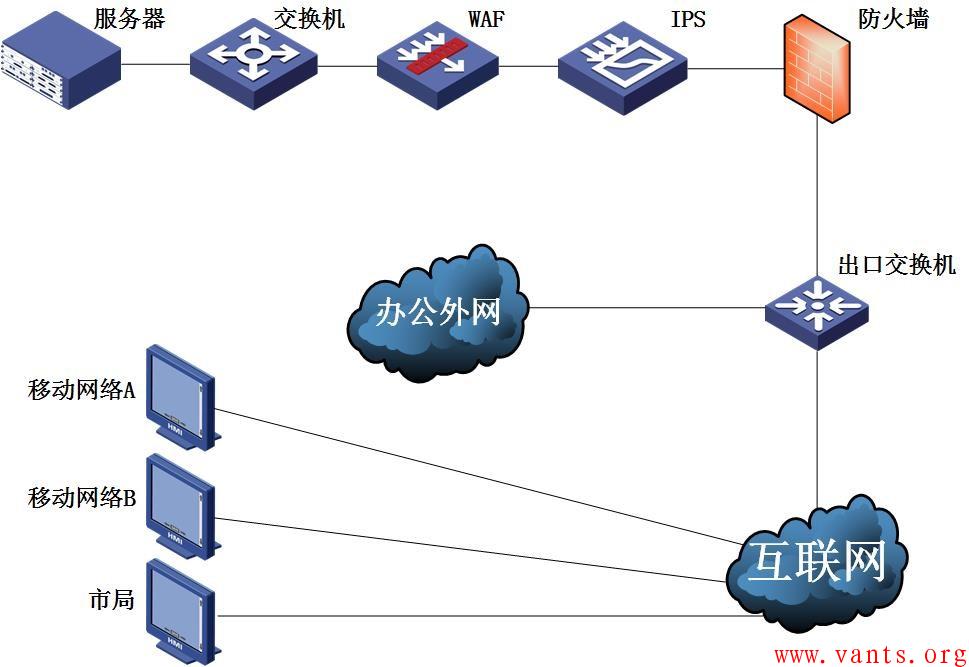
服务器通过交换机、WAF、IPS,经防火墙映射对外提供服务,办公外网与互联网通过出口交换机访问服务器。
1.2 情况简介
2017年11月17日有市局反应省局门户网站地市信息公开栏目访问异常。

点击信息公开栏目后如下图所示:
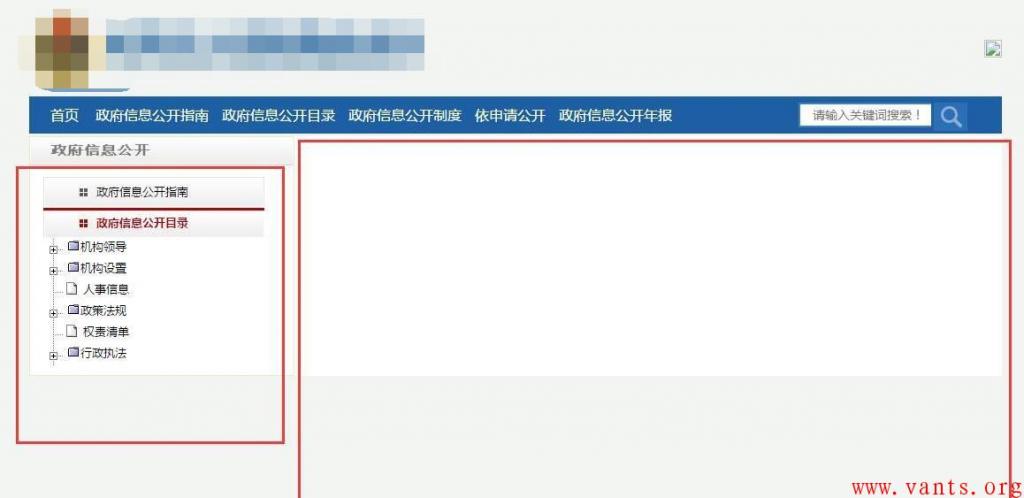
大部分市局...
-
QQ邮箱订阅

-
搜索
日历
最新日志
链接
分类

最新碎语
- 如果一个人想要做一件真正忠于自己内心的事情,那么往往只能一个人独自去做"——理查德·耶茨
2019-06-25 21:34
- 日后我们知道,真正的人生道路是由内心决定的。不论我们的道路看上去如此曲折、如此荒谬地背离我们的愿望,它终归还是把我们引到我们看不见的目的地。(茨威格《昨日世界》)
2019-03-16 21:27
- 如果你渴望得到某样东西,你得让它自由,如果它回到你身边,它就是属于你的,如果它不会回来,你就从未拥有过它。——大仲马《基督山伯爵》
2018-10-09 22:07
- 人生有两大悲剧:一个是没有得到你心爱的东西;另一个是得到了你心爱的东西。人生有两大快乐:一个是没有得到你心爱的东西,于是可以寻求和创造;另一个是得到了你心爱的东西,于是可以去品味和体验。——弗洛伊德
2018-09-25 18:06
- 一个人越有思想,发现有个性的人就越多。普通人是看不出人与人之间的差别的——布莱兹·帕斯卡尔
2018-08-30 18:44
存档
- 2020年11月(2)
- 2018年1月(1)
- 2017年12月(1)
- 2017年11月(6)
- 2017年6月(1)
- 2017年5月(1)
- 2017年4月(1)
- 2017年3月(1)
- 2016年11月(1)
- 2016年4月(1)
- 2015年7月(2)
- 2015年6月(1)
- 2015年5月(5)
- 2014年12月(1)
- 2014年11月(1)
- 2014年10月(1)
- 2014年8月(1)
- 2014年7月(1)
- 2014年6月(1)
- 2014年5月(1)
- 2014年4月(3)
- 2014年2月(2)
- 2014年1月(2)
- 2013年12月(1)
- 2013年11月(1)
- 2013年10月(2)
- 2013年9月(1)
- 2013年8月(1)
- 2013年7月(3)
- 2013年6月(2)
- 2013年5月(1)
- 2013年4月(3)
- 2013年3月(1)
- 2013年2月(2)
- 2013年1月(2)
- 2012年12月(11)
- 2012年11月(12)
- 2012年10月(12)
- 2012年9月(26)
- 2012年8月(29)
- 2012年7月(18)
- 2012年6月(2)
- 2012年5月(25)
- 2012年4月(16)
- 2012年3月(13)
- 2012年2月(6)
标签
blogger

