
【转】iptables的nf_conntrack相关参数引起两个问题
作者:易隐者 发布于:2016-4-23 11:49 Saturday 分类:案例讨论
【说在之前】:
近段时间在处理一个故障时,网上查找相关资料时看到的一篇文章,作者处理故障时的态度和思路堪称技术牛典范,特转发过来分享给大家。
【原文作者】:phanx
【原文链接】:http://blog.chinaunix.net/uid-7549563-id-4912055.html
【原为全文】:
========phanx.com========
Author: phanx
Updated: 2015-3-23
转载请保留作者信息
=========================
某关键业务系统上频繁出现业务失败,并发生了一次大规模业务中断。
该系统采用两台IBM Power 740运行AIX 6.1+Oracle 11gR2 RAC作为数据库服务器,两台DELL PowerEdge R720作为应用服务器,前端采用F5作为负载均衡设备。
数据库服务器和应用服务器之间有Cisco ASA5585硬件防火墙进行访问控制。
应用服务器上运行自行开发的C程序,通过Oracle Client提供的接口,以长连接的方式访问RAC数据库。
故障时,先检查了数据库服务器的系统负载,发现相对于正常时期,CPU负载偏高,IO负载明显升高,IOPS达到13000左右。
正常时的负载

异常时的负载

检查数据库相关日志,发现有大量的TNS错误:
- Fatal NI connect error 12170.
- VERSION INFORMATION: VERSION INFORMATION:
TNS for IBM/AIX RISC System/6000: Version 11.2.0.3.0 - Production
TCP/IP NT Protocol Adapter for IBM/AIX RISC System/6000: Version 11.2.0.3.0 - Production
Oracle Bequeath NT Protocol Adapter for IBM/AIX RISC System/6000: Version 11.2.0.3.0 - Production
VERSION INFORMATION:
TNS for IBM/AIX RISC System/6000: Version 11.2.0.3.0 - Production
TCP/IP NT Protocol Adapter for IBM/AIX RISC System/6000: Version 11.2.0.3.0 - Production
Oracle Bequeath NT Protocol Adapter for IBM/AIX RISC System/6000: Version 11.2.0.3.0 - Production
VERSION INFORMATION:
TNS for IBM/AIX RISC System/6000: Version 11.2.0.3.0 - Production
TCP/IP NT Protocol Adapter for IBM/AIX RISC System/6000: Version 11.2.0.3.0 - Production
Oracle Bequeath NT Protocol Adapter for IBM/AIX RISC System/6000: Version 11.2.0.3.0 - Production
VERSION INFORMATION:
TNS for IBM/AIX RISC System/6000: Version 11.2.0.3.0 - Production
TCP/IP NT Protocol Adapter for IBM/AIX RISC System/6000: Version 11.2.0.3.0 - Production
Oracle Bequeath NT Protocol Adapter for IBM/AIX RISC System/6000: Version 11.2.0.3.0 - Production
Mon Feb 23 13:22:16 2015
Time: 23-Feb-2015 13:22:16
*********************************************************************** Time: 23-Feb-2015 13:22:16
Time: 23-Feb-2015 13:22:16
Time: 23-Feb-2015 13:22:16
Tracing not turned on.
Tracing not turned on.
Fatal NI connect error 12170.
Tracing not turned on.
Tracing not turned on.
Tns error struct:
Tns error struct:
VERSION INFORMATION:
TNS for IBM/AIX RISC System/6000: Version 11.2.0.3.0 - Production
TCP/IP NT Protocol Adapter for IBM/AIX RISC System/6000: Version 11.2.0.3.0 - Production
Oracle Bequeath NT Protocol Adapter for IBM/AIX RISC System/6000: Version 11.2.0.3.0 - Production
Tns error struct:
Tns error struct:
ns main err code: 12535
ns main err code: 12535
Time: 23-Feb-2015 13:22:16
ns main err code: 12535
ns main err code: 12535
Tracing not turned on.
Tns error struct:
TNS-12535: TNS:operation timed out
TNS-12535: TNS:operation timed out
TNS-12535: TNS:operation timed out
ns secondary err code: 12560
ns main err code: 12535
TNS-12535: TNS:operation timed out
ns secondary err code: 12560
ns secondary err code: 12560
nt main err code: 505
ns secondary err code: 12560
nt main err code: 505
nt main err code: 505
nt main err code: 505
TNS-12535: TNS:operation timed out
TNS-00505: Operation timed out
TNS-00505: Operation timed out
ns secondary err code: 12560
TNS-00505: Operation timed out
nt secondary err code: 78
nt secondary err code: 78
nt main err code: 505
TNS-00505: Operation timed out
nt secondary err code: 78
nt OS err code: 0
nt OS err code: 0
nt secondary err code: 78
nt OS err code: 0
Client address: (ADDRESS=(PROTOCOL=tcp)(HOST=10.1.32.70)(PORT=37975))
TNS-00505: Operation timed out
nt OS err code: 0
Client address: (ADDRESS=(PROTOCOL=tcp)(HOST=10.1.32.70)(PORT=25972))
Client address: (ADDRESS=(PROTOCOL=tcp)(HOST=10.1.32.70)(PORT=9108))
nt secondary err code: 78
Client address: (ADDRESS=(PROTOCOL=tcp)(HOST=10.1.32.70)(PORT=52073))
nt OS err code: 0
Client address: (ADDRESS=(PROTOCOL=tcp)(HOST=10.1.32.70)(PORT=49148))
- Mon Feb 23 13:22:16 2015
再检查应用服务器端,发现应用服务进程大量处于Busy状态,无法处理应用数据。再检查应用服务器到数据库的连接情况,发现数据库上报告timeout的连接,在应用服务器上仍然处于ESTABLISHED状态。
- [sysadmin@appsrv1 ~]$ netstat -an|grep 10.1.197.15
- tcp 0 0 10.1.32.70:37975 10.1.197.15:1521 ESTABLISHED
- tcp 0 0 10.1.32.70:25972 10.1.197.15:1521 ESTABLISHED
- tcp 0 0 10.1.32.70:9108 10.1.197.15:1521 ESTABLISHED
- tcp 0 0 10.1.32.70:52073 10.1.197.15:1521 ESTABLISHED
- tcp 0 0 10.1.32.70:49148 10.1.197.15:1521 ESTABLISHED
- .
- .
- .
- .
这时候,怀疑是不是ASA阻断了数据库和应用之间的连接。检查ASA配置后发现超时时间设置的是8个小时,这个业务在低谷期也不会出现8小时空闲,并且应用程序会在空闲的时候定期探测数据库长连接是否可用。
因此,觉得不太可能是常见的空闲超时导致的连接中断。 继续进行分析,发现数据库里面有较多的direct path read 等待事件。观察应用SQL的执行计划,发现有大量的全表扫描,并且某些SQL的执行时间较长,
超过了60秒。 很显然这是常见的11g Direct Path Read的副作用,要么让应用开发组去优化SQL,要么关掉11g的针对串行的直接路径读。这样就会缓解系统IO繁忙的情况。这样SQL的执行时间也会降低,如果在
合理的范围内,就不会引发这个故障了。
但是,仅仅是这个原因,应该不会引起TNS Time out的情况,性能不好,SQL执行时间过长,只是让这个问题浮现了出来,并不是这个故障的根本原因。
所以还得继续分析是什么导致应用服务器和数据库服务器之间的已建立连接被单向断掉。
应用组把挂死的服务器进程kill掉后,重启了服务进程,业务暂时是恢复了。
这时候,让应用组找到连接中断时执行的相应的SQL和连接端口,再找到网络组的兄弟帮忙,从Riverbed Cascade上提取了RAC一个节点和其中一个APP的对应端口的通信流,用wireshark打开进行分析。
我们从ARW和ASH报告中发现引起中断的情况中,SQL执行时间都较长,基本达到了5分钟左右。 然后针对这些执行较长的SQL的连接数据流分析,应用服务器在提交SQL执行请求后等待数据库服务器回复。
数据库服务器在执行完以后返回数据给应用服务器时,应用服务器就一直无法接收到数据了,然后数据库服务器就一直重传,直到超时,然后报错TNS Time out。

从这个TCP流上可以清楚看到,appsrv1在12:20.040144的时候提交了SQL执行请求,紧接着收到了racdb1的ACK报文,说明racdb1成功接收了这个请求,并且开始执行。
在15:55.30881的时候,racdb1执行完这个SQL后开始向appsrv1返回结果,SQL执行了215秒左右。这时候,appsrv1没有任何回应。直到最后超时,racdb1发出重置连接的RST报文。
这个情况,总是感觉不对,为什么appsrv1莫名其妙的不响应了呢? appsrv1并没有宕机,网络连接也正常的,百思不得其解。 最后想实在没有办法的话,只能到appsrv1上去抓包看看。
由于appsrv1比较繁忙,在无法确定故障发生的情况下持续抓包的记录数据肯定会相当庞大,并且肯定会对应用服务器造成较大的压力,并且存储空间也是个问题。
这时候,应用组的人报告说偶尔会有一两个服务进程出现挂死的情况。 于是决定去碰碰运气,设好capture条件,只抓取与racdb1的通信,与其余关联应用服务器的包全部过滤掉,抓了5分钟,就已经有20个G的数据了。
这么大的数据,我的4G内存i3小破本子开起来都是个问题,于是找了一台强力的测试服务器,传上去看看。 翻着翻着发现了一些TCP重传,看起来像故障的现象了,但是发现appsrv1对于重传却返回了
ICMP Host Administratively Prohibited,并不是完全没有反应。 于是再找网络组按照时间段提取数据,发现故障时是一样的,在racdb1重传的时候,appsrv1每个重传都回应了ICMP Host Administratively Prohibited。
原来,网络组的哥们从Riverbed Cascade里面提取数据流的时候是设定了只提取TCP相关端口的报文,ICMP报文就被漏掉了,没有提取出来。于是,重新提取故障时候的TCP流和相关数据包。

这个时候就可以看到完整的信息了。确实每个重传都有回应的。
TCP流是建立起来的,iptables里面也应该也有正常的流状态信息,为什么会被appsrv1拒绝呢?
继续对appsrv1进行检查,发现 /etc/sysctl.conf里面配置了这么一句
net.netfilter.nf_conntrack_tcp_timeout_established = 300
就是它让iptables对于已建立的连接,300秒若没有活动,那么则清除掉,默认的时间是432000秒(5天)。
问是谁设置的这个参数,答复是应用组在上线前做性能测试时,按照应用供应商的建议修改的。为啥要改,为啥改成这个值也不清楚  。
。
好吧,应该就是它了,改回默认的值 432000 应该就能解决了。同时让应用组的优化优化SQL,就可以写故障报告了。
故事就到这里就完了? 当然不是。 在调整了这个值后,一开始还风平浪静。过了一段时间,应用组又来报告说,又出现了很少的
业务超时,而且有越来越频繁的趋势,从一天一两次到一条一二十次。真是不省心啊。。
继续了解情况,这次仿佛跟数据库服务器没啥关系了,是这个应用服务器到服务器总线应用之间的连接出现了问题。服务总线应用服务器向该应用服务器发起连接的时候,偶尔会被拒绝。
考虑到应用服务器之前有F5来作为负载均衡,先检查了F5上应用服务状态有没有异常,结果良好,F5上对应用的健康探测没有异常。 好吧,还是直接看数据流,为啥会拒绝应用连接。
服务总线应用服务器和该应用服务器之间通信是短连接,有业务调用的时候,由服务总线方发起连接。应用组找到了被拒绝的连接,通过debug日志找到相关端口信息,继续让网络组
提取相关连接数据包。

这里可以看到,在svcbus2向appsrv1发起请求后,同样有应答,但是一分钟后,svcbus2关闭了连接。再过了3分钟appsrv1处理完请求后返回数据给svcbus2的时候就被svcbus2给拒绝掉了,然后同样也是不停重传,最后超时。
应用组说svcbus2上,应用有一个60秒超时的机制,当对端在60秒内没有返回结果就直接关闭这个请求,断掉连接。
从上面的报文也可以看到,svcbus2发起了FIN报文,但是由于appsrv1没有处理完,所以这个连接关闭是单向的,直到appsrv1处理完成,重传数据超时,连接完全关闭。
这和svcbus2新建连接到appsrv1被拒绝有啥关系呢?我一时也没有想明白。 appsrv1上的iptables对于服务端口应该是一直开放的,不应该拒绝新建的连接啊,除非这个新建的连接有什么特殊的地方。
通过红帽的客户网站,找到了一些相关信息。
https://access.redhat.com/solutions/73353 iptables randomly drops new connection requests
- if /proc/net/ipv4/netfilter/ip_conntrack_tcp_loose is set to 1, iptables creates a new connection-tracking entry after receiving any packet, not just packets with the SYN flag set
- the ip_conntrack_tcp_loose setting is useful in firewalls for keeping already established connections unaffected if the firewall restarts, but this causes issues in the following scenario:
- a client initiates a new connection with the same source port it used in a previous connection
- the server already has an iptables connection-tracking entry for the same IP address and port, with states ESTABLISHED and UNREPLIED
- the default rule gets hit, instead of the desired one
- the packet is dropped, and the server returns icmp-host-prohibited
https://access.redhat.com/solutions/73273 Why iptables sporadically drops initial connections requests?
This behavior is caused by enabling ip_conntrack_tcp_loose sysctl parameter which enables iptables to create a conntrack entry whenever it sees any packet from any direction and not just SYN packet.
This is called connection picking and is usually used by the firewalls to ensure that the ongoing end to end sessions remain active if for some reason the firewall gets restarted. But this feature is not needed in standalone servers.
这里面提到了iptables在规则为allow的情况下也会对某些数据包drop的情况。大意就是在默认情况下(/proc/net/ipv4/netfilter/ip_conntrack_tcp_loose 为1时),iptables会对即时是不完整的TCP连接也会记录其状态,这样避免
iptables重启的时候影响已有的连接,但是会影响一些特殊情况。
我们的应用正好就出现了这种特殊情况。当svcbus2因为等待appsrv1应答超时的时候,关闭了连接。而appsrv1上的nf_conntrack表中,当收到svcbus2发送的FIN包是,对于这个连接的记录会变成CLOSE_WAIT状态,然后在60秒后,
条目被清除。 但是,当appsrv1开始回应数据的时候,nf_conntrack表中又出现了这个连接的条目,并且状态是ESTABLISHED [UNREPLIED]。
- [root@appsrv1 ~]# grep 51522 /proc/net/nf_conntrack
ipv4 2 tcp 6 35 CLOSE_WAIT src=10.1.32.70 dst=10.1.41.192 sport=9102 dport=51522 src=10.1.41.192 dst=10.1.32.70 sport=51522 dport=9102 [ASSURED] mark=0 secmark=0 use=2
.
- .
- wait more seconds
- .
- .
- [root@appsrv1 ~]# grep 51522 /proc/net/nf_conntrack
- ipv4 2 tcp 6 431965 ESTABLISHED src=10.1.32.70 dst=10.1.41.192 sport=9102 dport=51522 [UNREPLIED] src=10.1.41.192 dst=10.1.32.70 sport=51522 dport=9102 mark=0 secmark=0 use=2
这个条目,由于默认的net.netfilter.nf_conntrack_tcp_timeout_established = 432000 的影响,会一直保持5天,直到红色那个值变为0才会被清除。 这就导致了当svcbus2再以相同的源端口51522向appsrv1发起连接的时候,appsrv1的iptables
会拒绝掉这个请求。
那是不是设置net.ipv4.netfilter.ip_conntrack_tcp_loose=0就行了呢,副作用怎么消除呢?
反复想了想,还是不想就这样了,决定看看有没有其它更优的方法。
到测试环境模拟这个故障,服务端口就用TCP 8888,客户机源端口就用TCP 22222
- 1.配置服务器的iptables 允许tcp 8888端口.
- 2.用python来建立一个监听服务,监听在tcp 8888.
- [root@server ~]# python
- Python 2.6.6 (r266:84292, Sep 4 2013, 07:46:00)
- [GCC 4.4.7 20120313 (Red Hat 4.4.7-3)] on linux2
- Type "help", "copyright", "credits" or "license" for more information.
- >>> import socket
- >>> serversocket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
- >>> serversocket.bind(("0.0.0.0",8888))
- >>> serversocket.listen(5)
- >>> (clientsocket, address) = serversocket.accept()
- 3. 从客户端以tcp 22222为源端口发起连接,并发送请求数据
- [root@client ~]# python
- Python 2.6.6 (r266:84292, Sep 4 2013, 07:46:00)
- [GCC 4.4.7 20120313 (Red Hat 4.4.7-3)] on linux2
- Type "help", "copyright", "credits" or "license" for more information.
- >>> import socket
- >>> s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
- >>> s.bind(("0.0.0.0",22222))
- >>> s.connect(("1.1.1.101",8888))
- >>> s.send("request",100)
- 在server端检查iptable contrack 的状态
- [root@server ~]# grep 103 /proc/net/nf_conntrack
- ipv4 2 tcp 6 431949 ESTABLISHED src=1.1.1.103 dst=1.1.1.101 sport=22222 dport=8888 src=1.1.1.101 dst=1.1.1.103 sport=8888 dport=22222 [ASSURED] mark=0 secmark=0 use=2
- Wait some seconds, then close the connection on client.
- >>> s.close()
- >>> exit()
- 继续检查server端的iptable contrack 状态
- [root@server ~]# grep 103 /proc/net/nf_conntrack
- ipv4 2 tcp 6 54 CLOSE_WAIT src=1.1.1.103 dst=1.1.1.101 sport=22222 dport=8888 src=1.1.1.101 dst=1.1.1.103 sport=8888 dport=22222 [ASSURED] mark=0 secmark=0 use=2
- [root@server ~]# sleep 55
- [root@server ~]# grep 103 /proc/net/nf_conntrack
- server端的条目消失了.
- 4. 当server端向client发送响应数据的时候
- >>> clientsocket.recv(1000)
- 'request'
- >>> clientsocket.send("respond",100)
- 再到server端查看iptable contrack 状态就会发现有 ESTABLISHED[UNREPLIED] 条目.
- 但是看TCP 连接的状态却是 CLOSE_WAIT.
- [root@server ~]# grep 103 /proc/net/nf_conntrack
- ipv4 2 tcp 6 431996 ESTABLISHED src=1.1.1.101 dst=1.1.1.103 sport=8888 dport=22222 [UNREPLIED] src=1.1.1.103 dst=1.1.1.101 sport=22222 dport=8888 mark=0 secmark=0 use=2
- [root@server ~]# netstat -ntp|grep 103
- tcp 1 7 1.1.1.101:8888 1.1.1.103:22222 CLOSE_WAIT 28978/python
- 这个时候,从wireshark上抓包也发现了client拒绝server的响应数据并发送ICMP[host administratively prohibited].
- 当server端TCP连接CLOSE_WAIT超时后, 受到net.netfilter.nf_conntrack_tcp_timeout_established参数的控制,nf_contrack表中ESTABLISHED[UNREPLIED] 条目是依然存在的。
- [root@server ~]# netstat -ntp|grep 103
- [root@server ~]# grep 103 /proc/net/nf_conntrack
- ipv4 2 tcp 6 431066 ESTABLISHED src=1.1.1.101 dst=1.1.1.103 sport=8888 dport=22222 [UNREPLIED] src=1.1.1.103 dst=1.1.1.101 sport=22222 dport=8888 mark=0 secmark=0 use=2
- 监听端口状态是正常的
- [root@server ~]# netstat -nplt|grep 8888
- tcp 0 0 0.0.0.0:8888 0.0.0.0:* LISTEN 28978/python
- 5. 这个时候,当client再以tcp 22222为源端口向tcp 8888发起连接,server端的iptables就拒绝了这个SYN报文. client端连接报错。
- [root@client ~]# python
- Python 2.6.6 (r266:84292, Sep 4 2013, 07:46:00)
- [GCC 4.4.7 20120313 (Red Hat 4.4.7-3)] on linux2
- Type "help", "copyright", "credits" or "license" for more information.
- >>> import socket
- >>> s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
- >>> s.bind(("0.0.0.0",22222))
- >>> s.connect(("1.1.1.101",8888))
- Traceback (most recent call last):
- File "
", line 1, in - File "
", line 1, in connect - socket.error: [Errno 113] No route to host
- >>>
经过这个模拟,也验证了故障的成因,那么要解决问题,就简单了。
有两边可以想办法,一是appsrv1这边,如果让该条目早点过期,那么只要端口重用不是特别快的情况下,这个问题就不会发生。
在不改造应用的情况下,这是一个较好的临时解决方案,但是过期时间设多久,要先要满足前一个问题的SQL最长执行时间,然后观察端口重用的时间有没有短于SQL最长执行时间。
appsrv1这边存在条目的原因是返回数据被拒绝后的TCP重传数据包被iptables nf_conntrack记录,svcbus2又没有响应的TCP回应报文。
那么另外一个方法就是如果能让svcbus2正常响应就解决了。 怎么能正常解决呢?
iptables nf_contrack 还有另外一个参数 net.netfilter.nf_conntrack_tcp_timeout_close_wait。 默认是60秒跟TCP的CLOSE_WAIT 超时时间是一致的。通过试验模拟这个故障发现,如果把这个时间设长,超过TCP CLOSE_WAIT 超时时间,
那么在TCP连接关闭后,appsrv1的返回报文还可以到达svcbus2的内核, svcbus2会直接发送TCP RST包将这个连接重置。这样appsrv1上的TCP连接和nf_contrack中的条目都会清除掉。
看模拟的过程。

当 appsrv-test 在svcbus-test发送FIN连接后过了127秒开始发送响应数据,这时候svcbus-test就立刻回应了RST报文,后来svcbus-test半个小时候在重新再用tcp 22222端口向appsrv-test tcp 8888发起连接的时候,问题问题,连接可以正常建立了。
当然这种处理方法应用层会收到错误,要对这个错误进行处理才行。
由于第二种方法还涉及应用代码的调整和测试,因此通过观察发现SQL最长执行时间在15分钟左右,服务总线源端口重用时间大概在4个小时,但是由于重用源端口的时候,目标端口还不一定是appsrv上的对应端口,因此4小时不一定形成冲突。
综合考虑了一下,设置
net.netfilter.nf_conntrack_tcp_timeout_establishe=7200
是一个比较合适的解决方法。调整后,经过近期的观察,没有出现业务失败了。
经验:
系统参数调整要小心,特别是对应用行为不清楚的情况下,要多测试。该业务系统就是没有经过严格的测试,为了赶目标节点匆匆上线继而发生后续故障。
另外,在系统软件部署的时候,管理员使用的文档中没有及时更新,缺乏了对Oracle 11g一些容易引起问题的新特性参数进行调整的要求。当遇到应用
没有充分优化的情况下,由于这个新特性带来的性能加速恶化,也对相关故障产生了间接的影响。 因此及时更新文档,保证系统的参数基线合理显得也很重要。
最后,运维工作纷繁复杂,要静下心来仔细的看,才会发现其中的小细节。
标签: 疑难杂症 ICMP iptables Host Administratively Prohibited nf_conntrack
PSH|RST同置位,系统应用共沉寂!
作者:易隐者 发布于:2014-2-7 14:34 Friday 分类:案例讨论
年前一位技术兄弟维护的站点遇到异常流量,导致无法正常访问站点。其将捕获到的报文发给我,让我帮其分析一下大致是什么情况。年前杂事较多,未来得及写分析文档,年后将未完成的部分补充完全,放在此供各位兄弟讨论。
我首先查看其TCP会话数较多(8500多个),而且大部分的TCP会话是219.140.167.122与X.X.254.18之间产生的,并且这些会话具有较为明显的流量特征,如下图所示:
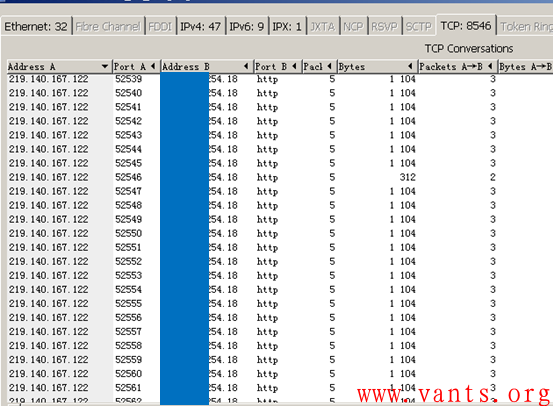
我们在报文 中任意查看其中一个TCP会话的交互报文,如下图:

我们可以发现,其在完成三次握手之后,219.140.167.122主机与X.X.254.18发起了一个PSH、RST同时置一的报文,如下图:
这个报文的解码和follow TCP Stream显示其为一个http get请求报文,如下:
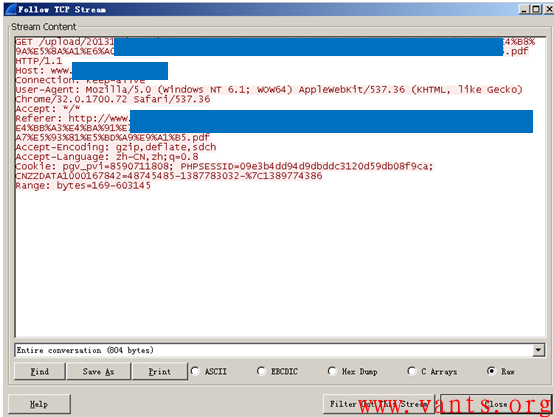
将其解码,如下:

可见这是一个针对站点某个pdf文档进行访问的操作。
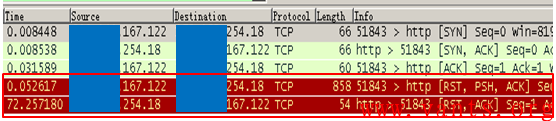
在这个TCP交互过程中,我们可发现服务器在收到这个PSH、RST位同时置一的get请求之后,并没有立即RST释放这个TCP连接,而是在72秒之后,服务器才向客户端发送RST报文释放该TCP连接。
一般情况下,在收到RST报文之后,系统传输层会立即释放对应的TCP连接,为什么要等到72秒之后才发送RST报文呢?TCP协议栈在收到PSH,RST位同时置一的报文时,应该如何处理??
Google百度均未找到相关的说明资料。
我们不妨自己先大胆推测一下服务器在收到PSH、RST位同时置一的报文时时如何处理。
三种假设:
1,如果服务器先处理RST位,则服务器端会立即释放相关的TCP连接表信息。PSH位置一应该会失去应有的意义,传输层不会将客户端的应用字段递交给应用层处理。
2,如果服务器先处理PSH位,后处理RST位,则服务器将get请求提交应用层之后,释放TCP连接。服务器及时向应用层在处理完客户端的get请求之后,应用层向传输层提交应用层响应数据,这时,会发现在服务器传输层已有的TCP连接表信息中找不到对应的TCP连接,传输层向应用层报错,应用层放弃。
3,如果服务器先处理PSH位,忽略RST位,则服务器会将应用层的响应字段正常发送给客户端。
我们再来仔细的看看上述报文交互的情况:
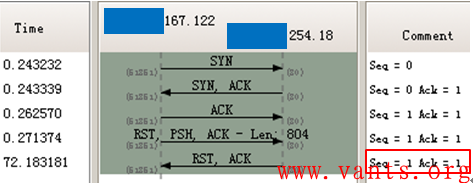
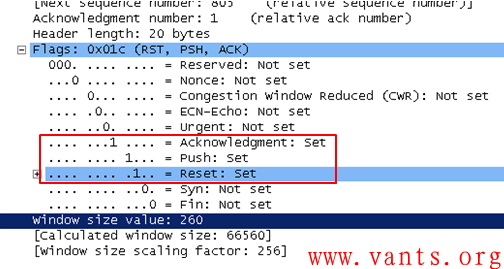
我们可以发现,服务器在72秒之后向客户端发送的RST报文其ACK位是置一的,ACK相对确认号是1,这说明这个RST报文发送出来的时候,服务器端的TCP连接表信息是正常的,并且传输层并未处理PSH、RST位置一的报文,否则ACK相对确认号应该是805而不是我们看到的1。
我们再来看一下这个服务器发送的RST报文的解码,如下图所示:
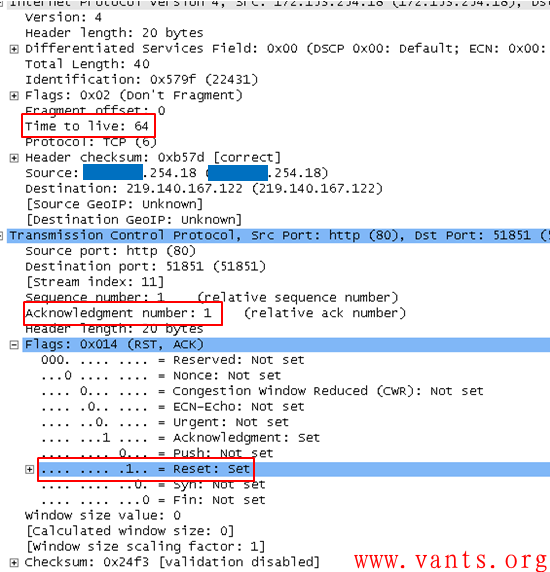
该报文TTL=64,可说明两点:
1,这个报文的确是服务器发送的,不会是第三方进行TCP会话劫持伪造发送的;
2,这个服务器可能是linux的服务器。
上面的这些说明了什么呢?
我个人认为,造成上述情况出现的原因是服务器过滤了RST位置一的报文!
服务器要做到对TCP标识位进行过滤并不是一件难事,iptables就可以。iptables如下命令即可实现对RST位置一报文的过滤:
iptables -A INPUT -p tcp --tcp-flags RST RST -j DROP
服务器过滤了PSH/RST位置一的报文,它不管PSH是否置一,因此那个客户端发送给服务器的PSH/RST位置一的http get报文并未被服务器传输层收到,服务器传输层在等待了72秒未收到客户端的任何请求之后,主动RST释放了这个TCP连接。
这些流量特征一致的TCP会话基本都是一样的,在三次握手建立TCP连接之后,向服务器发送PSH、RST位同时置一的http get请求报文,如下图所示:
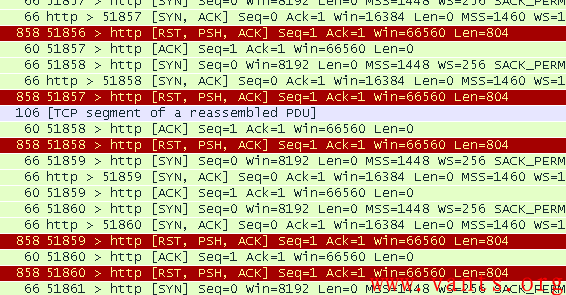
客户端短时间内大量的这种报文,导致服务器的连接表骤增而在一定时间内难以释放,从而给服务器造成了DOS攻击的效果。
标签: TCP RST TTL get push DOS攻击 连接表 异常流量 HTTP PSH RST过滤 iptables PSH/RST位同时置一
又遇TCP协议栈异常问题
作者:易隐者 发布于:2013-10-29 16:47 Tuesday 分类:案例讨论
大家还记得我以前写的《TCP确认机制异常案例》(链接为:http://www.vants.org/?post=200)吗?今天在一个用户那边再次遇到了一个TCP协议栈异常的问题。
用户反馈的问题现象是业务交互出现异常,难以定位异常出现的原因,我在用户现场分析了异常出现时的报文交互情况,如下图所示:
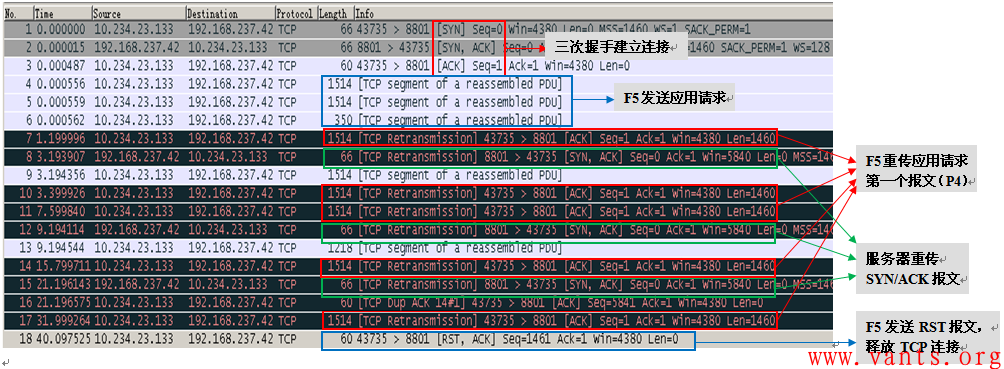
由F5设备主动向服务器发送SYN连接请求报文,服务器响应SYN/ACK报文,F5发送ACK报文确认后,向服务器连续发送3个大小分别为1514、1514、350大小的应用请求报文,但是1.199秒之后,F5重传了应用请求的第一个报文(该报文序列号为No7,该数据报其实是序号为No4的报文的重传),紧接着,2秒后,看到服务器的SYN/ACK的重传报文(该报文序列号为No8,该报文为No2报文的重传报文),后面数十秒的交互,基本是都是F5对应用请求报文的重传和服务器SYN/ACK报文的重传,在40秒之后,由F5主动发送RST报文释放该TCP连接。
由整个交互的过程,我们可以清晰的看到,服务器不断重传SYN/ACK报文,说明服务器没有正常处理F5的ACK报文(序列号为No3的报文),站在F5的角度,TCP连接已经建立成功,但是站在服务器的角度,却认为TCP连接未建立完成,因此服务器不断重传SYN/ACK报文,为什么服务器在明确收到了F5的三次握手的ACK报文,却没有正确处理呢?而且后续F5重传的应用请求报文(No7、No10、No11、No14、No17)都可以说是对服务器SYN/ACK报文的确认,但是服务器全部忽略了,因此,这基本上可以判断为服务器端系统的TCP协议栈出现异常,导致了应用出现了异常。
标签: TCP F5 应用故障 SYN 重传 TCP协议栈 应用异常
策略误报导致应用保存失败的分析案例
作者:易隐者 发布于:2013-4-20 14:13 Saturday 分类:案例讨论

查看这个交互的过程,我们可以非常清晰的看到,客户端与服务器TCP三次握手正常,问题出在客户端提交POST请求的报文被中间设备丢弃了。比较有趣的是,客户端在尝试两次重传之后,较为聪明的将这个POST请求字段(长度为859B)拆分为两个长度分别为536B和323B的字段,并先将长度为536B的应用字段重传给服务器,我们清楚的看到服务器对这个应用字段作出了确认,这说明这个长度的应用字段正常到达了应用服务器,但是后续长度为323B的应用字段一直被丢弃,这很容易想到是中间设备策略误报一直丢弃某些固定报文导致的,我们来看一下这个应用字段里到底封装的是什么应用数据,我们首先看这个报文的应用字段解码如下:


标签: 应用故障 IPS 策略误报 POST WAF SQL注入
《某公司QQ掉线分析案例》之我见
作者:易隐者 发布于:2013-4-14 17:52 Sunday 分类:案例讨论
大致看了分析过程之后,觉得其中存在一些疑问,特地找时间针对这个案例做一个大致的分析,以便大家讨论参考。原本准备做相关交互图示的,由于个人时间问题,这次就免了,还望各位见谅。
1, QQ多人同时掉线,大约1秒就自动连上,浏览网页和其他应用没有问题
QQ属于一种终端的应用,一般情况下,局域网内某应用出现同时掉线、缓慢等问题,基本上可以排除是单个终端的问题,因为从这个现象上来看,这是一个全局问题,可能是业务应用本身、业务服务器或者承载业务的网络系统出现了问题。在此故障分析案例中,作者提到QQ同时掉线但是浏览网页和其他应用没有问题。通过这个故障现象的描述,我个人首先可能会想到整个互联网出口是否会出现网络瞬间中断的情况?这是我个人的猜想,因为如果真是互联网出口出现网络瞬间中断,那么HTTP等基于TCP的应用由于TCP的重传机制,在出口网络中断1秒左右的时间内,终端使用者不会有明显的异常感受,而基于UDP等应用,可能会出现掉线等现象,在网络出口恢复正常之后,QQ再次自动上线。这个猜想的原因至少可以很好的解释该案例作者一开始描述的故障现象。
2, QQ掉线是QQ服务器主动RST连接导致的,腾讯给出的解释是由于用户端IP地址出现了变化。
1),QQ大部分情况下应该是使用UDP协议的,少数情况下使用TCP协议。
QQ是一个较为复杂的应用,其为了满足使用者在各种复杂的环境对QQ的正常使用,其会存在多种模式和网络交互行为,大部分情况下,QQ默认会使用UDP协议进行交互,少数情况下会使用TCP甚至TCP的80端口、443端口进行交互,特殊情况下,根据需要和设置,其还可以通过代理的方式进行交互。
在该案例中,测试机的QQ似乎使用的是TCP443端口进行交互的,但其实绝大部分情况下,QQ都是基于UDP协议进行交互的。因此在此案例中,按照我个人较为严谨的分析习惯,测试机的选择非常值得做进一步的商榷。
2),就算这个客户网络中所有使用的QQ都是基于TCP协议的,如果真是如腾讯所说,是由于QQ服务器发现用户IP出现了变化,才向客户端发送RST报文的,那么:
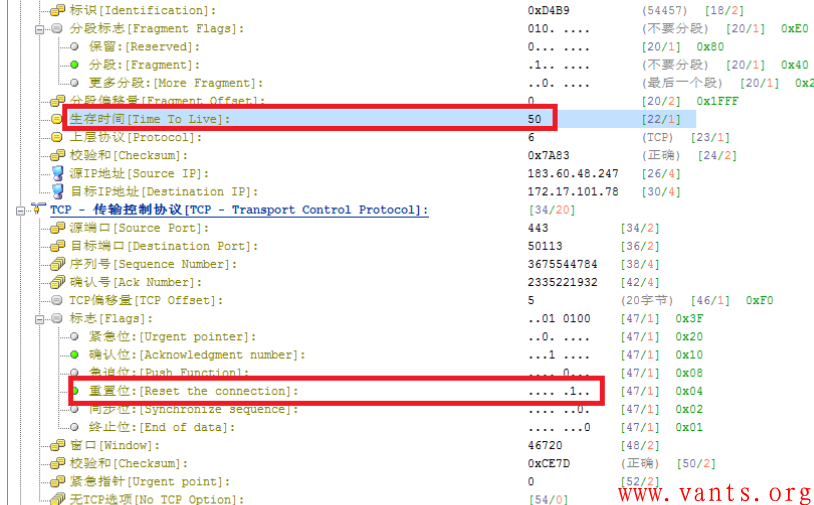
该RST报文ACK位是置一的,因此这个RST报文并不是如作者想象的情况下产生的。
其三,我们再来看另外一张截图:

3,如果真的是防火墙的NAT出现了这种低级的错误和BUG,那么对用户影响最大的应该是HTTP等基于TCP应用。因为很多HTTP应用的动态口令、验证码等都需要通过数个不同的TCP连接与服务器进行交互,一旦出现该案例作者所说的防火墙处理BUG,将导致这些应用出现访问故障。而不会仅仅是无关紧要的QQ应用出现问题。
4,QQ掉线而其他TCP应用正常,很可能是防火墙的UDP会话保持时间过短导致的。
因为很多人挂QQ并不一直与好友聊天。而一般情况下,防火墙等为节约设备资源,会将UDP的会话超时时间设置为一个较短的数值,如60秒,那么如果用户在这个超时时间内无任何数据交互的话,防火墙会将这个UDP会话从防火墙连接表中删除,当QQ客户端再次尝试与QQ服务器交互时,其发送的QQ状态更新报文就会被防火墙丢弃,导致QQ客户端掉线。QQ掉线后,客户端会再次发起新的连接,此时防火墙将其作为一个新建的UDP连接进行处理,QQ因此再次成功上线。当然这个很难解释QQ同时掉线的现象。
5,在NAT POOL情况下,NAT设备会根据不同的算法(基于源IP的、基于连接的等)实现NAT POOL的地址复用,大部分算法应该都是基于源IP等计算的,如果是基于数据包、连接等进行计算,则很可能会导致各种问题的产生,我以前有一个非常经典的案例——《移动无线VPN客户端隧道建立故障分析》,下次我发布到我的博客,大家可去参考。
简单总结:
-
QQ邮箱订阅

-
搜索
日历
最新日志
链接
分类

最新碎语
- 如果一个人想要做一件真正忠于自己内心的事情,那么往往只能一个人独自去做"——理查德·耶茨
2019-06-25 21:34
- 日后我们知道,真正的人生道路是由内心决定的。不论我们的道路看上去如此曲折、如此荒谬地背离我们的愿望,它终归还是把我们引到我们看不见的目的地。(茨威格《昨日世界》)
2019-03-16 21:27
- 如果你渴望得到某样东西,你得让它自由,如果它回到你身边,它就是属于你的,如果它不会回来,你就从未拥有过它。——大仲马《基督山伯爵》
2018-10-09 22:07
- 人生有两大悲剧:一个是没有得到你心爱的东西;另一个是得到了你心爱的东西。人生有两大快乐:一个是没有得到你心爱的东西,于是可以寻求和创造;另一个是得到了你心爱的东西,于是可以去品味和体验。——弗洛伊德
2018-09-25 18:06
- 一个人越有思想,发现有个性的人就越多。普通人是看不出人与人之间的差别的——布莱兹·帕斯卡尔
2018-08-30 18:44
存档
- 2020年11月(2)
- 2018年1月(1)
- 2017年12月(1)
- 2017年11月(6)
- 2017年6月(1)
- 2017年5月(1)
- 2017年4月(1)
- 2017年3月(1)
- 2016年11月(1)
- 2016年4月(1)
- 2015年7月(2)
- 2015年6月(1)
- 2015年5月(5)
- 2014年12月(1)
- 2014年11月(1)
- 2014年10月(1)
- 2014年8月(1)
- 2014年7月(1)
- 2014年6月(1)
- 2014年5月(1)
- 2014年4月(3)
- 2014年2月(2)
- 2014年1月(2)
- 2013年12月(1)
- 2013年11月(1)
- 2013年10月(2)
- 2013年9月(1)
- 2013年8月(1)
- 2013年7月(3)
- 2013年6月(2)
- 2013年5月(1)
- 2013年4月(3)
- 2013年3月(1)
- 2013年2月(2)
- 2013年1月(2)
- 2012年12月(11)
- 2012年11月(12)
- 2012年10月(12)
- 2012年9月(26)
- 2012年8月(29)
- 2012年7月(18)
- 2012年6月(2)
- 2012年5月(25)
- 2012年4月(16)
- 2012年3月(13)
- 2012年2月(6)
标签
blogger

