
《某公司QQ掉线分析案例》之我见
作者:易隐者 发布于:2013-4-14 17:52 Sunday 分类:案例讨论
大致看了分析过程之后,觉得其中存在一些疑问,特地找时间针对这个案例做一个大致的分析,以便大家讨论参考。原本准备做相关交互图示的,由于个人时间问题,这次就免了,还望各位见谅。
1, QQ多人同时掉线,大约1秒就自动连上,浏览网页和其他应用没有问题
QQ属于一种终端的应用,一般情况下,局域网内某应用出现同时掉线、缓慢等问题,基本上可以排除是单个终端的问题,因为从这个现象上来看,这是一个全局问题,可能是业务应用本身、业务服务器或者承载业务的网络系统出现了问题。在此故障分析案例中,作者提到QQ同时掉线但是浏览网页和其他应用没有问题。通过这个故障现象的描述,我个人首先可能会想到整个互联网出口是否会出现网络瞬间中断的情况?这是我个人的猜想,因为如果真是互联网出口出现网络瞬间中断,那么HTTP等基于TCP的应用由于TCP的重传机制,在出口网络中断1秒左右的时间内,终端使用者不会有明显的异常感受,而基于UDP等应用,可能会出现掉线等现象,在网络出口恢复正常之后,QQ再次自动上线。这个猜想的原因至少可以很好的解释该案例作者一开始描述的故障现象。
2, QQ掉线是QQ服务器主动RST连接导致的,腾讯给出的解释是由于用户端IP地址出现了变化。
1),QQ大部分情况下应该是使用UDP协议的,少数情况下使用TCP协议。
QQ是一个较为复杂的应用,其为了满足使用者在各种复杂的环境对QQ的正常使用,其会存在多种模式和网络交互行为,大部分情况下,QQ默认会使用UDP协议进行交互,少数情况下会使用TCP甚至TCP的80端口、443端口进行交互,特殊情况下,根据需要和设置,其还可以通过代理的方式进行交互。
在该案例中,测试机的QQ似乎使用的是TCP443端口进行交互的,但其实绝大部分情况下,QQ都是基于UDP协议进行交互的。因此在此案例中,按照我个人较为严谨的分析习惯,测试机的选择非常值得做进一步的商榷。
2),就算这个客户网络中所有使用的QQ都是基于TCP协议的,如果真是如腾讯所说,是由于QQ服务器发现用户IP出现了变化,才向客户端发送RST报文的,那么:
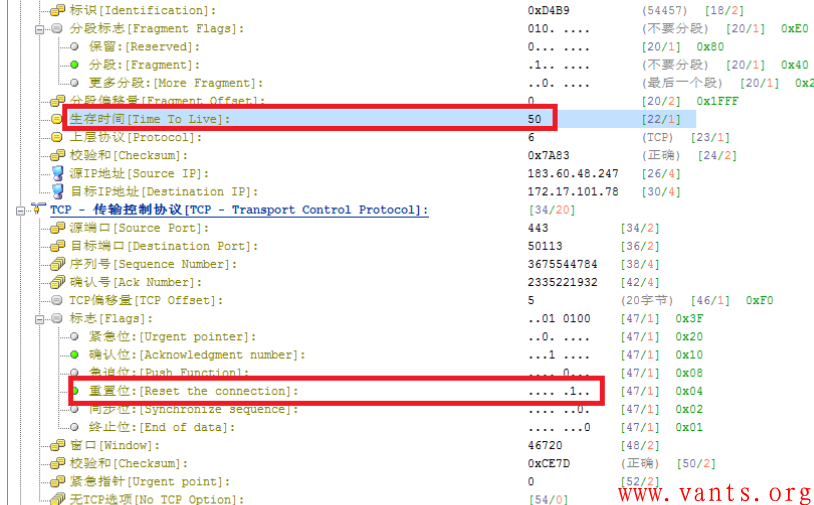
该RST报文ACK位是置一的,因此这个RST报文并不是如作者想象的情况下产生的。
其三,我们再来看另外一张截图:

3,如果真的是防火墙的NAT出现了这种低级的错误和BUG,那么对用户影响最大的应该是HTTP等基于TCP应用。因为很多HTTP应用的动态口令、验证码等都需要通过数个不同的TCP连接与服务器进行交互,一旦出现该案例作者所说的防火墙处理BUG,将导致这些应用出现访问故障。而不会仅仅是无关紧要的QQ应用出现问题。
4,QQ掉线而其他TCP应用正常,很可能是防火墙的UDP会话保持时间过短导致的。
因为很多人挂QQ并不一直与好友聊天。而一般情况下,防火墙等为节约设备资源,会将UDP的会话超时时间设置为一个较短的数值,如60秒,那么如果用户在这个超时时间内无任何数据交互的话,防火墙会将这个UDP会话从防火墙连接表中删除,当QQ客户端再次尝试与QQ服务器交互时,其发送的QQ状态更新报文就会被防火墙丢弃,导致QQ客户端掉线。QQ掉线后,客户端会再次发起新的连接,此时防火墙将其作为一个新建的UDP连接进行处理,QQ因此再次成功上线。当然这个很难解释QQ同时掉线的现象。
5,在NAT POOL情况下,NAT设备会根据不同的算法(基于源IP的、基于连接的等)实现NAT POOL的地址复用,大部分算法应该都是基于源IP等计算的,如果是基于数据包、连接等进行计算,则很可能会导致各种问题的产生,我以前有一个非常经典的案例——《移动无线VPN客户端隧道建立故障分析》,下次我发布到我的博客,大家可去参考。
简单总结:
标签: TCP RST 五元组 重传机制 防火墙 BUG NAT QQ掉线
由TCP保活引起的业务访问故障案例
作者:易隐者 发布于:2012-12-7 15:18 Friday 分类:网络分析
1 故障环境
1.1 故障拓扑
故障发生的网络拓扑结构如下图所示:
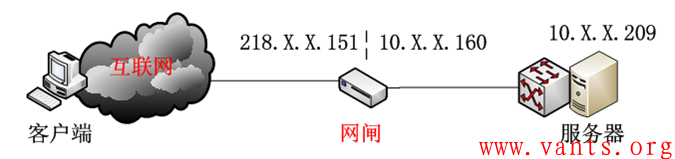
1.2 业务报文交互路径
1,客户端通过网闸映射地址218.X.X.151访问内部业务服务器10.X.X.209;
2,客户端经过网闸后,源地址变为网闸内口地址10.X.X.160访问真实的业务服务器。
2 故障现象
故障现象主要表现为:
客户端访问业务服务器出现中断现象,并且故障基本都发生是在夜间12点以后;
第二天重启网闸后,业务访问恢复正常,但是到夜间12点左右业务连接会再次中断;
在业务访问出现中断以后,偶尔会不定时的可以成功进行连接,但是持续时间不长就再次中断;
仅此业务应用存在这个异常,其他的业务基本正常。
3 故障分析
3.1 分析思路
考虑到故障都发生在夜间12点左右,因此在网闸内外网口同时部署网络分析产品,对内外网口交互的报文进行长时间的捕获存储,第二天,我们分别选取故障发生时间内的报文进行关联分析和对比分析。
3.2 分析过程
3.2.1 异常出现时,网闸外口的报文交互情况
我们选取故障发生时,网闸外网口的交互报文进行查看,我们在“TCP会话”视图中,发现了大量交互报文少、流量小、收发报文特征明显的TCP会话,如下图所示:
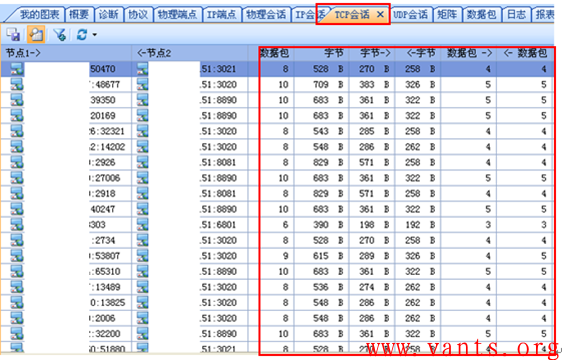
我们选取其中任意一个TCP会话,查看其详细的报文交互情况,如下图所示:
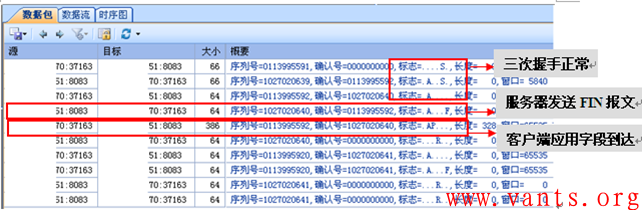
我们可以清楚地看到,客户端与服务器映射的外网地址通过三次握手建立TCP连接之后,服务器映射地址立即向客户端发送了FIN报文,主动释放TCP连接,后续的带有应用字段的客户端报文到达后,服务器直接向客户端回应RST报文。
我们查看了其他的TCP会话的详细报文交互情况,基本与上述情况一样。由此来看,似乎是网闸主动发送FIN报文导致了业务应用出现异常,网闸为什么会在已经建立三次握手之后立即主动发送FIN报文呢?难道是服务器主动发送的FIN报文?或者是网闸的BUG导致网闸主动发送FIN报文?我们需要在内网端做个关联对比分析才能确定。
3.2.2 在网闸内口发现保活报文
当我们取故障时内网的报文时,发现内网在做捕包存储时出现异常,抓包工具在故障出现之前崩溃了,并未将故障发生时的网闸内口报文捕获保存下来,而由于时间紧急,我们没有机会再花费一天的时间去捕获内网的报文,这些故障现场的不确定性现象发生了,我们只能抓取当下的网闸内口报文进行辅助分析。
我们在网闸内网口抓包发现大量的特征明显的TCP会话,如下图所示:
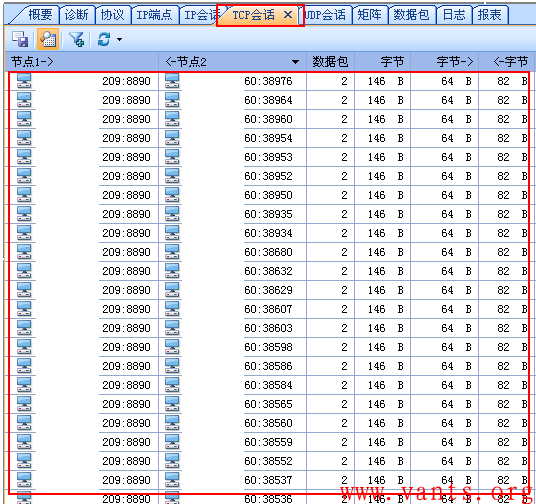
这些TCP会话仅有几个报文的交互,不像正常的业务数据交互报文,我们选择其中一个TCP会话查看其具体的交互报文,如下图所示:
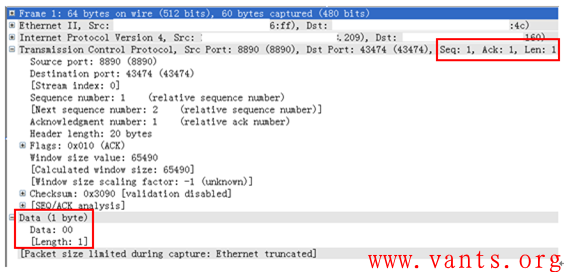
这是服务器发给客户端的报文,下面是客户端给服务器的报文:
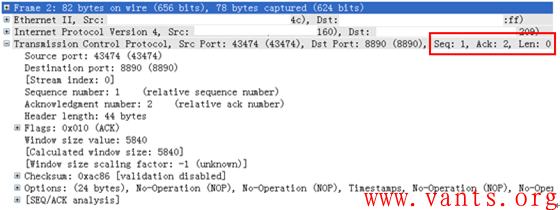
结合这两个报文,我们可以肯定,这是一个TCP保活报文。这些仅交互2个报文的TCP会话是服务器发给客户端的TCP保活行为!
3.2.3合理推测
这些数量众多的保活行为的TCP会话,引起了我们的关注,那么是否是保活行为导致业务应用出现问题呢?保活的功能之一是维持已有TCP连接,关于TCP保活的详尽描述大家可参考我博客的文章《TCP保活(TCP keepalive)》。
TCP保活的这个特性很自然的让我们想到可能是TCP保活功能引起网闸连接表满从而导致业务异常。但是网闸作为一个网关类设备一般都支持几十万甚至数百万的连接数,在无异常攻击报文的情况下不至于24小时连接表就全部满了,并且也只有这个业务应用出现异常,其他应用都是正常的。
我们发现外网的客户端访问到内网时,其源地址全部转换为网闸内口地址10.X.X.160,至此我们恍然大悟:源IP、源端口、目的IP、目的端口、协议类型等五元组信息决定一个连接,而在网闸内口,源IP、目的IP、目的端口、协议类型都已经确定,只有源端口是变换的,而端口范围只能在0-65535之间,还要去除一些常用的端口,如此一来,网闸内口跟服务器之间能够建立的TCP连接数只能在65535以内!
在这种情况下,客户端访问业务服务器的TCP连接在24小时内达到近65535个,从而导致后续的客户端与业务服务器无法正常建立连接,引起业务访问故障。
至于故障后又能偶尔连接正常但很快再次异常的原因也很好解释,那就是网闸内口在维护如此众多的连接时,总会由于各种原因导致几个连接异常释放,如此一来则紧接着的业务访问连接会正常建立,但是一旦用完为数不多的几个连接后,后续的业务连接将再次出现异常。
整个交互过程涉及到的客户端、网闸外口、网闸内口、服务器的状态变化如下图所示:
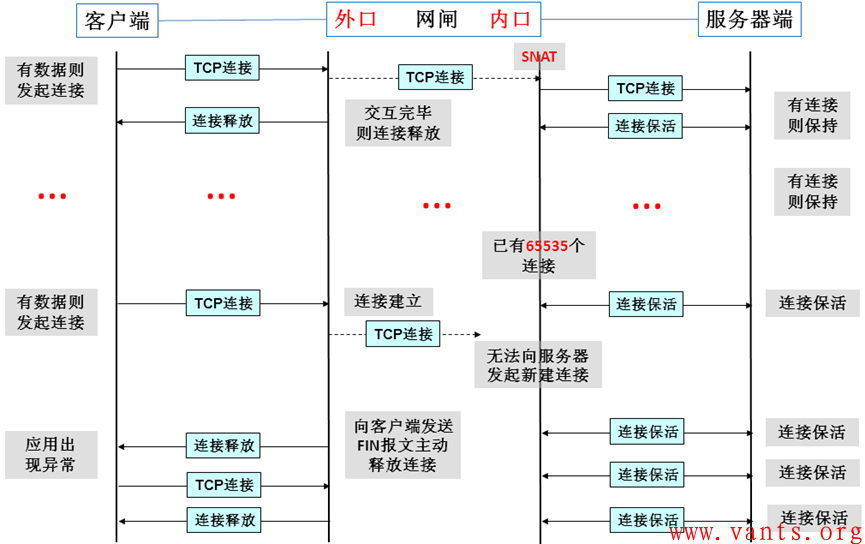
3.2.4验证
我们建议用户在下班后手动清空网闸内口已有连接,观察夜间12点故障是否出现来验证我们的推测。后经用户反馈,在清空连接后夜间12点左右故障未再现,如此充分证明我们上述的推测是正确的。
3.3 分析结论
服务器端设置了TCP保活功能,对所有的TCP连接主动实行TCP保活探测,这导致网闸内口与服务器建立的TCP连接无法得到释放,在24小时以内,TCP连接数接近65535个,而此时客户端再次发起与服务器之间的业务连接之后,网闸内口已经无法再与服务器新建TCP连接,如此导致业务连接无法建立。
4 故障解决
在找到导致此业务故障的真正原因之后,我们就可以对症下药,通过任意选择如下几种方式之一来彻底解决这个故障:
1, 可以在服务器上关闭TCP保活功能;
2, 在网闸内口关闭源地址转换(SNAT)功能;
3, 将网闸内口TCP连接释放时间调整至小于服务器发送TCP保活的间隔时间,这样可以在服务器发送保活报文之前,让网闸内口提前释放该连接;
4, 网闸内口使用TCP连接复用功能,让大部分的外网客户端访问连接仅通过少量的内部连接实现正常的业务交互,而服务器则可以与网闸内口之间少量连接保持保活。
标签: 疑难故障 五元组 连接表 TCP保活 TCP keepalive 连接复用 网闸 SNAT
连接数相关知识
作者:易隐者 发布于:2012-9-19 19:58 Wednesday 分类:网络分析
连接数是网络中非常重要的一个概念,在我们学习工作的过程中会经常遇到。下面将针对连接数相关的一些知识点做一些描述。
“连接数”是什么
不同产品对“连接数”的理解有一些差别,但是主流认为网络中交互双方的五元组信息决定了一个连接。所谓五元组信息是指源地址、源端口、目的地址、目的端口以及协议类型。连接数就是网络连接的数目。基本上TCP/UDP应用根据五元组信息都可以很好的对应于一个连接,但是对于ICMP协议,不同的产品会有一些不同的处理,考虑到ICMP报文在实际工作环境下非常少,相对于TCP、UDP应用的连接数基本上可以忽略,因此不针对此做深入的描述。
并发连接数
并发连接数是指同时在连接表中的连接数目。端系统和中间系统在处理这些连接时都会设置一个连接超时时间,在超时时间溢出之前,系统会为这些连接分配相应的存储资源。而我们熟知的Syn flood DOS攻击正是利用这个特性来达到攻击效果的。一般而言,并发连接数是衡量一个中间系统性能的指标之一。
每秒新建连接数
每秒新建连接数是一般是指中间设备在单位时间内(1秒内)所能建立连接的数量,这个参数的大小直接影响中间系统在单位时间内所能建立的最大连接数量,其也是衡量中间系统性能的一个重要指标。
连接数限制
连接数限制主要是指端系统或中间系统基于安全(防攻击)、管理(流量控制)等方面的需要而对某些IP的网络连接数量限制在某一范围内的策略。如windows系统中的连接数限制,防火墙路由器等中间系统上的“连接数限制”功能等。
端系统中的主机防火墙(如linux下的iptables)、操作系统本身、应用程序(Apche、IIS、数据库等)等都可能针对连接数进行限制,而现在常见的中间设备(防火墙、路由器等)基本上都支持连接数限制的功能,大家可以根据实际环境中的设备自行查阅相关手册的连接数有关功能的设置。
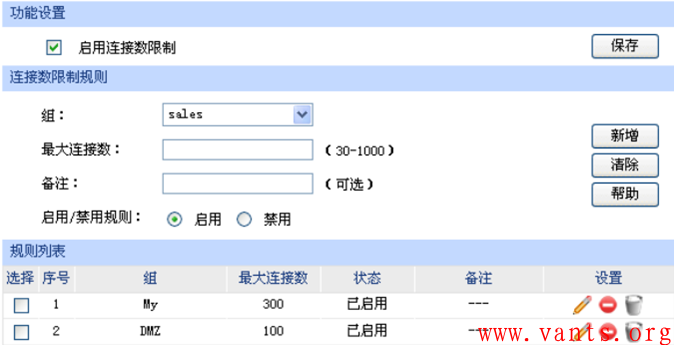
我们随便找个路由器上连接数限制功能设置的截图看看:
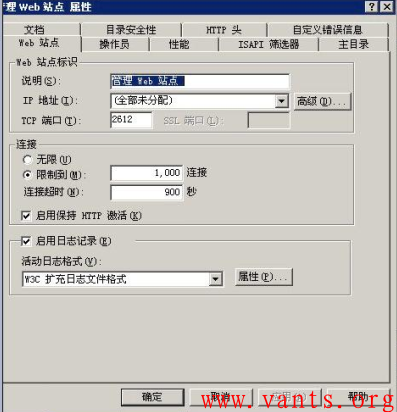
我们再来看看IIS连接数限制功能设置的截图:
连接数限制对网络的影响
连接数限制策略实施之后,当被限制连接数的IP超出限制的范围,其后续的网络连接将会被端系统或中间系统过滤丢弃,这将导致这些IP在进行网络交互时速度变慢、丢包等情况发生。因此,连接数限制是管理策略性导致网络交互异常的原因之一。
另外值得注意的是,在实际环境下,虽然端系统或中间系统可能会由于连接数限制功能丢弃部分报文,但是并不是所有设备在丢弃这些报文之后会向源主机发送ICMP差错通告报文,这给我们分析定位带来了一些难度。
标签: TCP 五元组 ICMP 连接数 连接数限制 并发连接数 每秒新建连接数
疑难网络故障的分析方法和原理之关联分析法
作者:易隐者 发布于:2012-7-4 12:51 Wednesday 分类:网络分析
前面我们在讲解对比分析法时,大家可能会有这样的疑问:对比分析法主要是通过对进出中间设备的数据包做对比分析,从而得出相关结论的,但是,我们都知道,很多中间设备会对经过它的数据包做一些修改和处理,那么我们怎么能够将进入设备前的数据包与被中间设备修改后转发出来的数据包对应起来呢?接下来这一节就是专门讲解我们如何将这些数据包关联起来的方法―—关联分析法。
关联分析法
数据包在经过各种中间设备时,经常会出现被中间设备(例如存储转发设备、NAT设备、负载均衡设备等)更改的情况,这对于我们分析问题非常不利,我们在做对比分析时,必须要将相应的数据流、数据包关联对应起来,否则就失去了可比性。
-
QQ邮箱订阅

-
搜索
日历
最新日志
链接
分类

最新碎语
- 如果一个人想要做一件真正忠于自己内心的事情,那么往往只能一个人独自去做"——理查德·耶茨
2019-06-25 21:34
- 日后我们知道,真正的人生道路是由内心决定的。不论我们的道路看上去如此曲折、如此荒谬地背离我们的愿望,它终归还是把我们引到我们看不见的目的地。(茨威格《昨日世界》)
2019-03-16 21:27
- 如果你渴望得到某样东西,你得让它自由,如果它回到你身边,它就是属于你的,如果它不会回来,你就从未拥有过它。——大仲马《基督山伯爵》
2018-10-09 22:07
- 人生有两大悲剧:一个是没有得到你心爱的东西;另一个是得到了你心爱的东西。人生有两大快乐:一个是没有得到你心爱的东西,于是可以寻求和创造;另一个是得到了你心爱的东西,于是可以去品味和体验。——弗洛伊德
2018-09-25 18:06
- 一个人越有思想,发现有个性的人就越多。普通人是看不出人与人之间的差别的——布莱兹·帕斯卡尔
2018-08-30 18:44
存档
- 2020年11月(2)
- 2018年1月(1)
- 2017年12月(1)
- 2017年11月(6)
- 2017年6月(1)
- 2017年5月(1)
- 2017年4月(1)
- 2017年3月(1)
- 2016年11月(1)
- 2016年4月(1)
- 2015年7月(2)
- 2015年6月(1)
- 2015年5月(5)
- 2014年12月(1)
- 2014年11月(1)
- 2014年10月(1)
- 2014年8月(1)
- 2014年7月(1)
- 2014年6月(1)
- 2014年5月(1)
- 2014年4月(3)
- 2014年2月(2)
- 2014年1月(2)
- 2013年12月(1)
- 2013年11月(1)
- 2013年10月(2)
- 2013年9月(1)
- 2013年8月(1)
- 2013年7月(3)
- 2013年6月(2)
- 2013年5月(1)
- 2013年4月(3)
- 2013年3月(1)
- 2013年2月(2)
- 2013年1月(2)
- 2012年12月(11)
- 2012年11月(12)
- 2012年10月(12)
- 2012年9月(26)
- 2012年8月(29)
- 2012年7月(18)
- 2012年6月(2)
- 2012年5月(25)
- 2012年4月(16)
- 2012年3月(13)
- 2012年2月(6)
标签
blogger

