
【转】交换机端口镜像,如何配置多个观察口
作者:易隐者 发布于:2012-12-27 12:40 Thursday 分类:参考资料
【说在之前】:
1,H3C和华为等多系列交换机均不支持多组镜像和多镜像监听口,这给有IDS、审计、网络分析等多种需要通过镜像采集流量的设备环境造成了诸多不便;
2,前段时间刚在用户故障现场发现有人使用交换机内回环巧妙实现了在H3C交换机环境下的多个监听采集需求,回来后一直想把这个方法写下来,只是在网上找了非常多的资料,均未有详细的说明,便耽搁下来,没想到今天就有人把这种方法整理了出来,实在巧合,正好转载于此,供大家参考;
3,这种镜像的方式,是否会导致报文被多次重复捕获?这是一个有待验证的问题,因为我们上次在用户现场发现通过这种方式镜像捕获的报文中有许多是重复捕获的,有试验环境的兄弟可以做一个详细的实验,拿出来供大家分享。
【原文连接】:
http://support.huawei.com/ecommunity/bbs/10152503.html
【原文作者】:
huang8880
【原文全文】:
实现原理:将所有端口镜像报文引入一个观察端口,通过观察端口内部环回(配置loopback internal),将报文在vlan内广播道其它若干实际观察端口,报文出端口时剥除vlan id。
配置举例:
预留vlan3500(for example)
#
vlan batch 3 10 20 100 300 to 301 3000 to 3002 3500 4000
#
观察端口
#
observe-port 1 interface GigabitEthernet0/0/21 vlan 3500
#
三个镜像端口:
#
interface GigabitEthernet0/0/3
port-mirroring to observe-port 1 both
#
interface GigabitEthernet0/0/4
port-mirroring to observe-port 1 both
#
interface GigabitEthernet0/0/5
port-mirroring to observe-port 1 both
#
三个观察端口:
#
interface GigabitEthernet0/0/11
port link-type trunk
undo port trunk allow-pass vlan 1
port trunk allow-pass vlan 3500
#
interface GigabitEthernet0/0/12
port link-type trunk
undo port trunk allow-pass vlan 1
port trunk allow-pass vlan 3500
#
interface GigabitEthernet0/0/13
port link-type trunk
undo port trunk allow-pass vlan 1
port trunk allow-pass vlan 3500
#
环回端口:
#
interface GigabitEthernet0/0/21
description neibuhuanhui
loopback internal
mac-address learning disable
port link-type trunk
undo port trunk allow-pass vlan 1
port trunk allow-pass vlan 3500
stp disable
注意:如果交换机全局配置stp enable,需要在环回端口上配置stp disable,否则该端口如果接收到交换机自己发出去的stp报文,会将端口置为discarding状态,环回报文都会在入向被丢弃
别具匠心的HTTP应用层行为设计
作者:易隐者 发布于:2012-12-26 16:09 Wednesday 分类:网络分析
今年的年初,有位兄弟在QQ跟我讨论一个较为少见的报文交互情况,我当时在看了具体的报文交互之后,对他说是某种HTTP探测机制,他则对我说有人认为是某种SACK的重传机制,记得我曾说过我会找时间好好研究一下这个交互的行为,后来的确也写了一些分析、画了一些图示,但是在未完成的情况下被耽搁了,直至最近才把这个翻出来,闲话少说,我们还是直奔主题,一起来看一下这个有意思的应用交互行为吧。
这个报文交互过程如下:

其交互的数据流图如下:
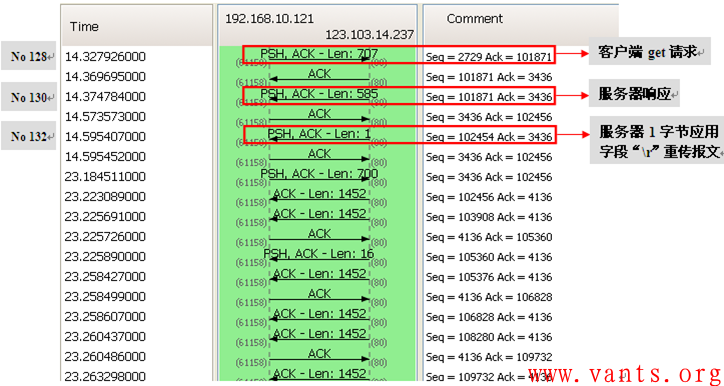
我们再来看一下其中几个重要报文的详细解码,首先看服务器的HTTP 200 OK响应报文的解码,如下图所示:
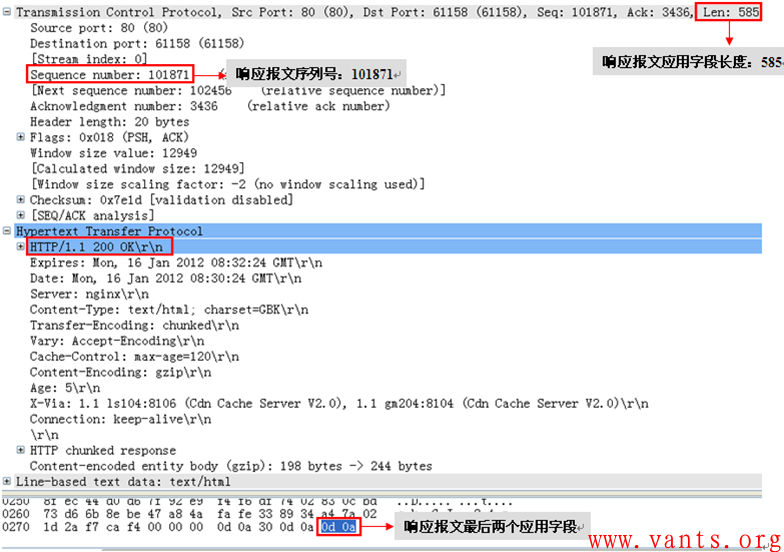
服务器响应报文解码(No128报文解码)
这个服务器的响应报文,其应用字段长度为585字节,序列号为101871,最后两字节应用字段为Hex 0d0a,我们再来看一下客户端对这个服务器响应报文的确认报文的解码,如下图所示:
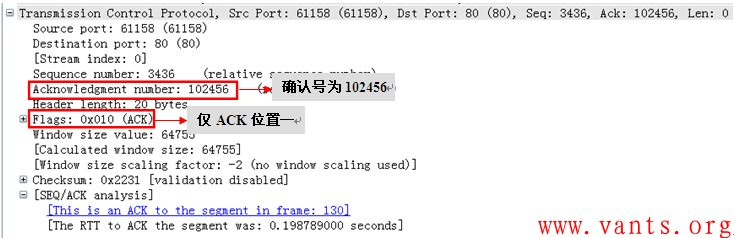
从上图解码来看,这是一个最为常见的确认报文,确认号为102456(101871+585)。我们再看看服务器的重传报文解码,如下:
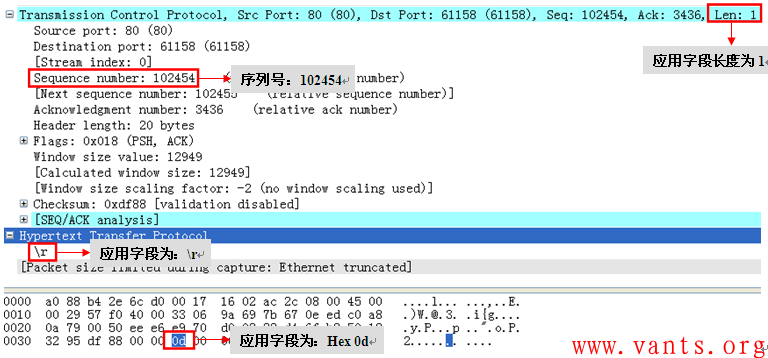
服务器后续重传报文解码(No132报文解码)
我们能够清楚的看到,这个来自服务器的重传报文其应用字段为1字节,序列号为102454,应用字段为Hex 0d,通过序列号我们可以看出这个重传报文并不是No130应用响应报文的重传,而仅仅是重传了No130报文中倒数第二个字节的应用字段!我们再看看客户端对服务器这个重传报文(No132报文)进行确认的报文解码:
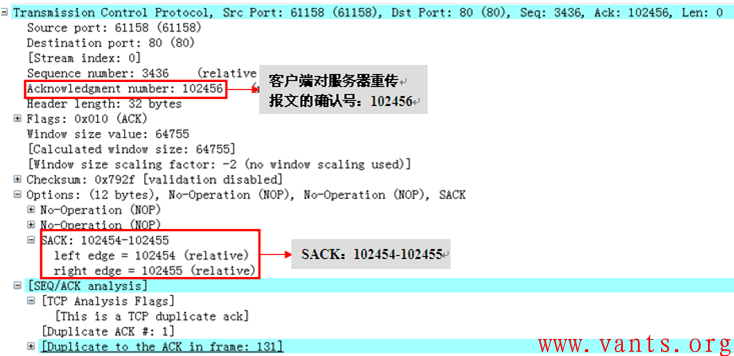
客户端对服务器这个重传报文(No132报文)进行确认的报文解码
客户端确认号为102456,但是其SACK却显示为102454-102455!确认号大于块左边界、块右边界值,这是不符合SACK的相关规范的!
我把这个交互过程制作一个更为清晰明了的图示如下:
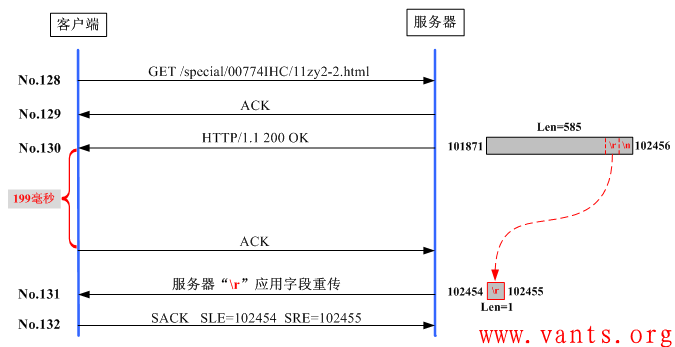
现在大家应该清楚这个交互的具体情况了,那么疑问来了:
1, 服务器端为何重传倒数第二个字节的应用字段?
2, 客户端在确认服务器的重传报文时,为何使用不规范的SACK?
带着这两个疑问,我用自己的机器访问163网站,重现了这个交互过程如下:
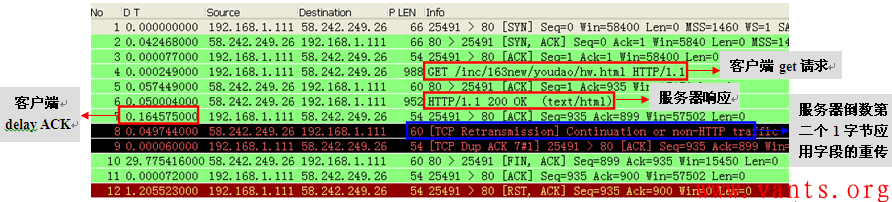
这个过程跟上面的交互过程几乎是一致的,我们就不再做详细的分析了,但是我们来仔细的查看一下客户端对服务器一字节应用字段重传的确认报文的解码:
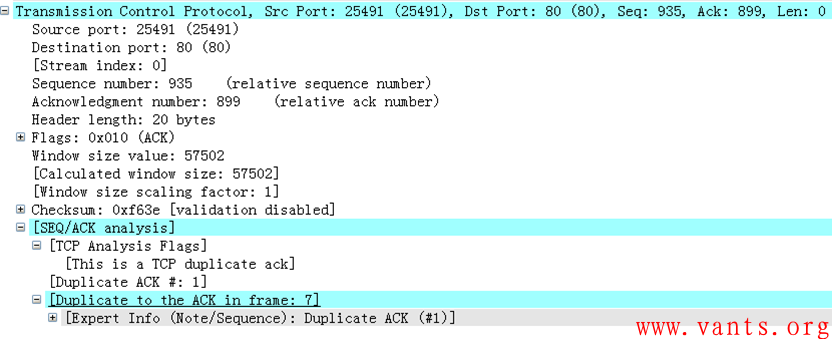
客户端对服务器重传报文进行确认的报文解码
在这个解码中,我们看到,我的机器在对服务器的一字节重传报文进行确认时,并未使用SACK,而是正常的重传了对服务器应用响应报文的确认,这是一般情况下的正常处理。这也说明了服务器的这个“重传一字节应用字段”的行为并不会导致客户端的确认出现异常。只有系统处理差异才能够解释这种情况的发生:我使用的客户端是XP操作系统,而那位与我讨论的兄弟使用的是其他操作系统。不同的操作系统在遇到这种重传部分应用字段的报文时处理机制不一样导致了疑问2的出现,这种不合SACK规范的确认报文虽然不会对服务器造成交互的影响,但足以让我们产生困惑,因此,严格来说,那位与我讨论的兄弟所使用的端系统如此处理是异常的。
如此我们解决了第二个疑问。
而针对第一个疑问,问遍了google和baidu无果后,让我们一起来分析一下这种行为可能带来的好处和坏处。
服务器在作出应用响应之后,在200ms左右未收到来自客户端的确认报文,则将倒数第二个字节的应用字段封装重传给客户端。
这样做的好处是在如下几种情况下会提高服务器与客户端的交互效率:
1, 服务器发往客户端的应用响应报文在网络传输过程中被丢弃
服务器的响应报文被丢弃,未到达客户端,在这种情况下,服务器的这个“200ms内未收到客户端ACK报文则重传一字节应用字段”的行为,避免了服务器端被动等待客户端确认报文到达直至重传定时器清零,服务器才可以重传报文,服务器通过这种行为主动探测客户端对服务器报文接收的情况,提高了交互的效率。
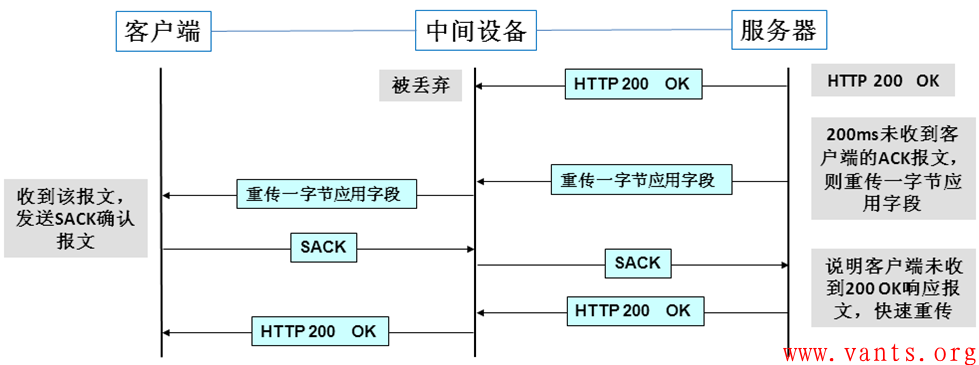
服务器应用响应报文被丢弃时的交互过程图示
2,客户端对服务器应用响应报文的确认在网络传输过程中被丢弃
如果客户端对服务器应用响应报文的确认报文在到达服务器之前被丢弃了,那么,会出现服务器端等待客户端确认报文到达的情况,这是一个超时重传的等待时间,一般至少在数秒之间,而服务器的这个“200ms内未收到客户端ACK报文则重传一字节应用字段”的行为,可以在200ms左右主动发送“封装最后倒数第二个字节应用字段的重传报文”,这个报文到达客户端之后,客户端将重新发送确认报文,这减少了超时重传的等待时间,从而提高了交互的效率;
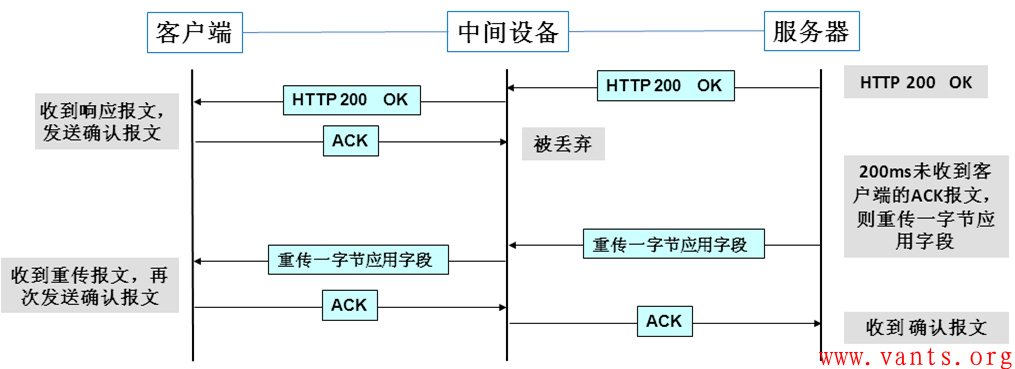
客户端对服务器响应报文的确认被丢弃时交互过程的图示
坏处就是:与一般正常交互过程相比,可能会给网络多带来两个64字节的小包。
如果客户端正常收到了服务器的应用响应报文,只是客户端的ACK报文较慢(网络传输延时或者客户端的delay ack机制等)到达服务器,则服务器会发送这种带有一个应用字段的重传报文,而客户端在收到这个报文后,会对这个报文进行确认。
而这个坏处相对于其带来的好处而言,实在不值一提,因此不得不说,这个HTTP应用行为的设计是别具匠心的!
那么为什么是倒数第二个字节而不是倒数第一个字节、倒数第三个字节或者其他字节?理论上来说重传任何一个字节达到的效果都是一样的,只重传部分应用字段(一个字节)是为了节约网络带宽资源,或许程序设计者如此设计有一些特别的用处,但是这只能去问程序设计者本人了。
另:我已将相关报文文件作为附件上传至此,有兴趣的兄弟姐妹可下载学习探讨,下载后解压即可使用wireshark直接打开查看。
附件下载:
别具匠心的HTTP应用行为设计-兄弟提供的原报文.zip 203.32KB
别具匠心的HTTP应用行为设计-我重现的报文1.zip 2.1KB
别具匠心的HTTP应用行为设计-我重现的报文2.zip 4.21KB
标签: sack 解码 重传 get delay ack HTTP 应用行为
【转】VPN Tunnel 口MTU问题解决
作者:易隐者 发布于:2012-12-24 14:00 Monday 分类:案例讨论
【说在之前】:
1,这个帖子是我在锐捷的论坛里看到的,现象很特别,值得研究讨论一番;
2,原帖中仅对故障做了描述,并未给出导致故障产生的根本原因,大家可以自行先考虑考虑,并尝试分析推测一下可能的原因,可在此贴下留言以供探讨;
3,此案例的正确答案应该已由回复中的liuquyong兄弟给出,主要原因在于加解密次数的减少导致了ERP交互性能的提升。关键就在于下面这张来自于思科的加解密流程图:
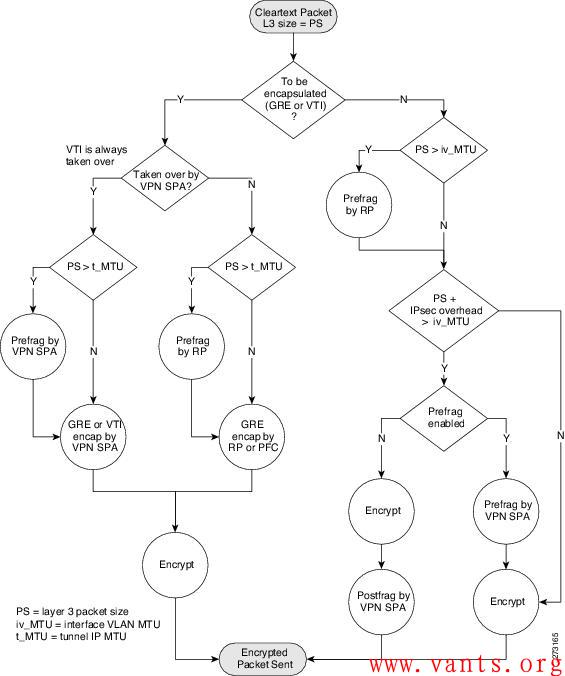
【原文连接】:
http://support.ruijie.com.cn/showtopic-22758.aspx
【原文全文】:
Gre隧道,Tunnel接口的MTU值设置为大于1500的值,有效吗?带着这个问题我讲讲今天遇到的问题:
NPE20(总部,版本RGNOS 9.12)与NBR300(分部,版本RGNOS 9.12)建立Tunnel 0接口的GRE隧道。
2010年初的时候刚开始用Tunnel功能,当时show interface tunnel 0 显示的 Tunnel 的 MTU值 1464,此时分部访问总部的ERP(用友U890,C/S架构,通过Tunnel隧道来访问的)很慢,卡!只要一遇到分部客户端与服务器之间有数据交互的时候,就异常的卡,有时软件直接无响应。
命令行将此Tunnel的MTU值设置为65535,此时访问速度“嗖”的立刻上去,只能用两个字形容:流畅!
前天,我将NPE20和NBR300都升级到最新的9.17 2P1 B4版本,9.17的Web控制界面操控性以及网速都有一定的提升,但这时出现问题,Tunnel的MTU值设置为65535之后,会自动变回1464,企业内的应用再度变卡,就和上述曾经遇到的卡的情况一样。并且无论如何都不像9.12版本那样保持65535。
此问题一直延续到今天。于是迫于无奈,在咨询了锐捷400电话客服之后,由3034号客服帮我将NPE20、NBR300都刷回9.12版本。刷回9.12版本之后的tunnel 0 先是保持1464默认值,这时还是卡,没有任何起色。手动将MTU值设置为65535,分部访问总部的ERP访问速度和响应速度一下子就上去了,非常流畅!
在咨询3034客服之前,我也咨询过几个客服关于MTU值的问题,得到的答案基本上都是类似于“公网传输数据包的MTU 最大只能1500" 、 “你设置为65535实际上没有效果”之类的话。并且让我两端互ping来测试是否丢包,互ping的时候的确是不丢包的,就算互ping的时候的指定ping包的大小也基本不丢包。
但是我想说,这只是理论,而我所遇到的问题是事实,事实胜于雄辩,Tunnel 0 的MTU为1464时与65535时相比,企业分部与总部之间的内部应用访问速度效果提升是:绝对异常明显的!!
所以,在这里我第一想说感谢3034客服帮我恢复到9.12,这个可以保存手动设置的65535MTU值的版本。第二我想恳请锐捷能够在下一个RGNOS版本中将GRE隧道的Tunnel 接口的这个MTU值改为可以保存用户手动配置的值,比如手动设置为65535,而别再自动恢复理论默认的1464之类的值。
因为今天我遇到的问题的确是:相对与MTU1464的默认值,MTU 65535时的隧道内访问速度是:提升绝对异常明显的!所有的事实,3034号客服可以证明!问题虽解决了,但是他也比较纳闷比较难解释。
我其实很纠结,我想用9.17 2P1 B4的新特性,包括上外网的网速也有一定的提升,但是无奈只能用9.12这个老版本。
标签: 丢包 故障 交互 MTU ping tunnel接口 GRE 锐捷
HTTP chunked编码异常导致业务下载附件慢故障案例
作者:易隐者 发布于:2012-12-18 9:32 Tuesday 分类:案例讨论
故障现象
某业务应用系统基于B/S架构开发,其应用页面打开正常,但是该应用在下载附件时,速度非常慢。
故障分析
在下载附件很慢时,在服务器上捕获客户端与服务器业务交互的报文。其TCP会话交互的情况如下图所示:
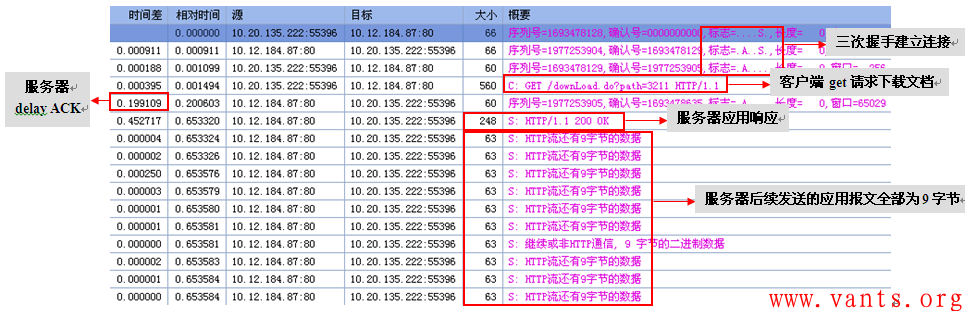
我们首先分析客户端与服务器三次握手建立连接的情况,查看客户端、服务器协商的MSS值是否正常,我们首先查看客户端SYN报文,其TCP MSS协商为1460,如下图所示:

接下来查看服务器SYN/ACK报文,其TCP MSS也为1460,如下图所示:
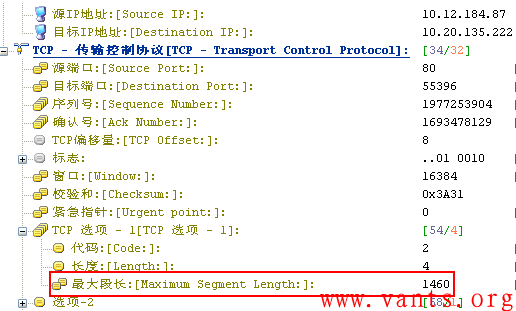
这说明双方协商的MSS值不存在问题,另服务器对客户端的get请求的第一个应用响应报文长度为248B,如下图所示:
这也充分说明业务服务器在给客户端发送报文时并不是一直只能发送9字节的报文。那么是什么原因导致业务服务器突然之间只能每次发送9字节的应用层数据呢?
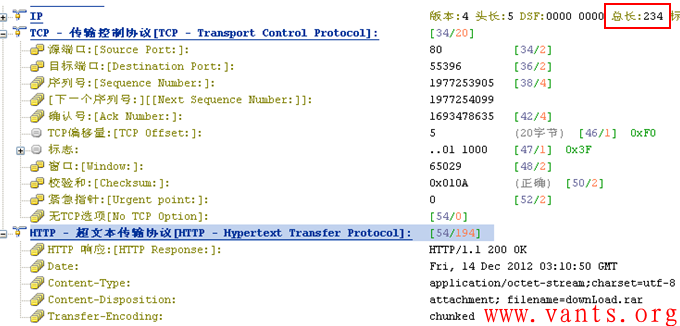
我们注意到服务器给客户端的第一个HTTP应用响应报文,如下图所示:

其Transfer-Enconding是chunked。
HTTP为什么会使用chunked传输编码?我直接引用《HTTP1.1中CHUNKED编码解析》一文中的描述来说明:“一般HTTP通信时,会使用Content-Length头信息性来通知用户代理(通常意义上是浏览器)服务器发送的文档内容长度,该头信息定义于HTTP1.0协议RFC 1945 10.4章节中。浏览器接收到此头信息后,接受完Content-Length中定义的长度字节后开始解析页面,但如果服务端有部分数据延迟发送吗,则会出现浏览器白屏,造成比较糟糕的用户体验。
解决方案是在HTTP1.1协议中,RFC 2616中14.41章节中定义的Transfer-Encoding: chunked的头信息,chunked编码定义在3.6.1中,所有HTTP1.1 应用都支持此使用trunked编码动态的提供body内容的长度的方式。进行Chunked编码传输的HTTP数据要在消息头部设置:Transfer-Encoding: chunked表示Content Body将用chunked编码传输内容。根据定义,浏览器不需要等到内容字节全部下载完成,只要接收到一个chunked块就可解析页面.并且可以下载html中定义的页面内容,包括js,css,image等。”
“Chunked编码一般使用若干个chunk串连而成,最后由一个标明长度为0的chunk标示结束。每个chunk分为头部和正文两部分,头部内容指定下一段正文的字符总数(非零开头的十六进制的数字)和数量单位(一般不写,表示字节).正文部分就是指定长度的实际内容,两部分之间用回车换行(CRLF)隔开。在最后一个长度为0的chunk中的内容是称为footer的内容,是一些附加的Header信息(通常可以直接忽略)。”
《HTTP1.1中CHUNKED编码解析》一文中使用了下图作为chunked解码的示意:
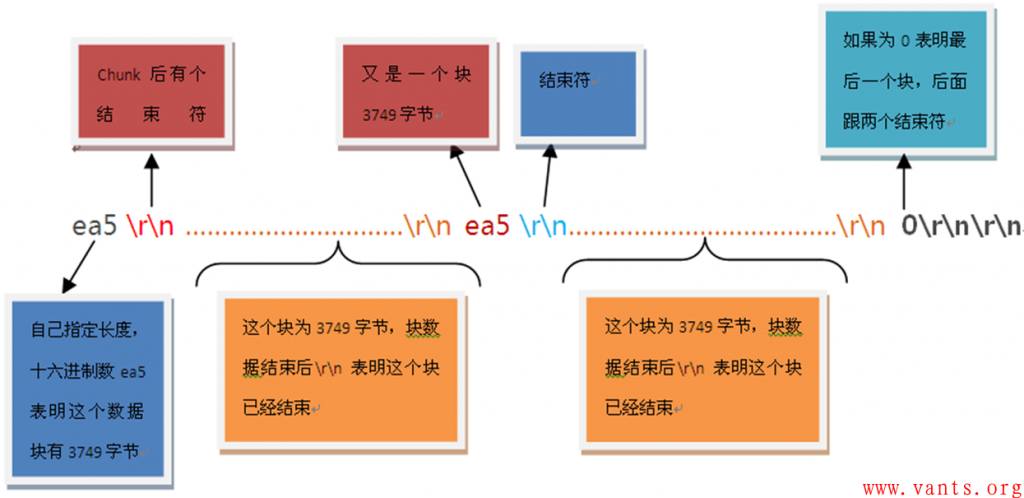
通过这张示意图,我们可以清晰的了解到,chunked解码主要由2块组成,一块为指定数据块长度,以\r\n回车换行作为结束符,另一块为实际的应用数据,也以\r\n回车换行作为结束符。
知道了chunked解码的组成,我们再来看看业务服务器给客户端发送的应用层长度仅9字节的报文解码:
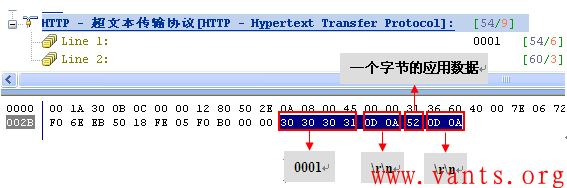
根据这9个字节的应用字段解码,我们将其十六进制换算为正常的十进制,如下表所示:

我们根据上图即可解码服务器发往客户端的chunked编码报文,其意义为:
1,指明长度为0001,即为1字节;
2,该报文真正的应用数据仅为1字节的“R”!
服务器每次仅传输一个字节给客户端!其报文的有效载荷率仅为: 1/63=0.015873015873015873015873015873016!
如果客户端下载一个1MB大小的附件,服务器端将产生1*1024*1024=1048576个报文,如果客户端每个报文都确认的话,一个下载将产生1048576次交互,即使往返时间RTT值非常小,再乘以1048576的基数之后,也将是个难以接收的数值。
如此,我们终于明白下载附件慢的原因了。
分析结论
此为业务服务器HTTP chunked编码传输时,自己指定的数据块长度值太小(为1字节)导致的故障。
参考文档
1,《HTTP1.1中CHUNKED编码解析》
2,RFC 2616《超文本传输协议》
标签: 疑难故障 MSS RTT 往返时间 HTTP chunked编码 交互次数
应用层保活行为
作者:易隐者 发布于:2012-12-17 10:53 Monday 分类:网络分析
我之前专门针对TCP保活撰写了一篇较为详细的说明文章——《TCP保活(TCP keepalive)》,在传输层主要通过TCP的保活功能来实现连接的保持,当时我也提到应用层的保活功能,但是应用层的保活功能在实际工作中较为少见,因为如果TCP能够提供保活功能的话,应用层一般就可以利用TCP的保活功能来实现连接的保活,但是毕竟应用层跟传输层是有区别的,一方面并不是所有的应用层会话都需要实现保活功能,另一方面TCP是针对传输层的,一旦开启TCP保活功能,将对所有基于TCP的应用产生影响,这些影响可能会是负面的,如我博客里的案例:《由TCP保活引起的业务访问故障案例》,这也是运维管理者不愿意看到的,因此,有些应用自行设计自己的应用层保活行为。
近期在用户的工作环境中,看到了如下图所示的应用层交互行为:
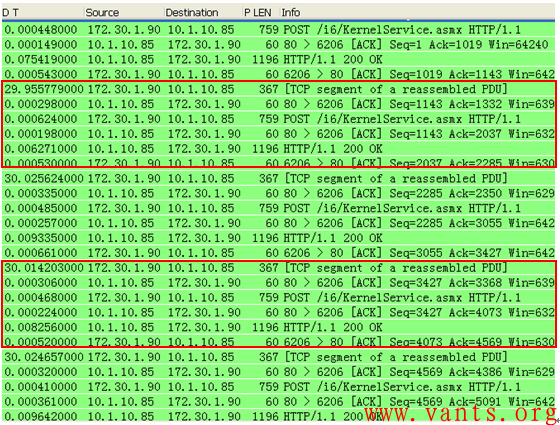
大家可以清晰的看到,这个交互过程具有以下行为特征:
1, 客户端每间隔固定时间(30秒)发出同样的请求;
2, 每次交互的报文都是一致的(客户端的请求、服务器的响应、报文长度等);
个人认为这些行为特征足以证明该交互过程是应用层设置的应用连接保活探测行为。
-
QQ邮箱订阅

-
搜索
日历
最新日志
链接
分类

最新碎语
- 如果一个人想要做一件真正忠于自己内心的事情,那么往往只能一个人独自去做"——理查德·耶茨
2019-06-25 21:34
- 日后我们知道,真正的人生道路是由内心决定的。不论我们的道路看上去如此曲折、如此荒谬地背离我们的愿望,它终归还是把我们引到我们看不见的目的地。(茨威格《昨日世界》)
2019-03-16 21:27
- 如果你渴望得到某样东西,你得让它自由,如果它回到你身边,它就是属于你的,如果它不会回来,你就从未拥有过它。——大仲马《基督山伯爵》
2018-10-09 22:07
- 人生有两大悲剧:一个是没有得到你心爱的东西;另一个是得到了你心爱的东西。人生有两大快乐:一个是没有得到你心爱的东西,于是可以寻求和创造;另一个是得到了你心爱的东西,于是可以去品味和体验。——弗洛伊德
2018-09-25 18:06
- 一个人越有思想,发现有个性的人就越多。普通人是看不出人与人之间的差别的——布莱兹·帕斯卡尔
2018-08-30 18:44
存档
- 2020年11月(2)
- 2018年1月(1)
- 2017年12月(1)
- 2017年11月(6)
- 2017年6月(1)
- 2017年5月(1)
- 2017年4月(1)
- 2017年3月(1)
- 2016年11月(1)
- 2016年4月(1)
- 2015年7月(2)
- 2015年6月(1)
- 2015年5月(5)
- 2014年12月(1)
- 2014年11月(1)
- 2014年10月(1)
- 2014年8月(1)
- 2014年7月(1)
- 2014年6月(1)
- 2014年5月(1)
- 2014年4月(3)
- 2014年2月(2)
- 2014年1月(2)
- 2013年12月(1)
- 2013年11月(1)
- 2013年10月(2)
- 2013年9月(1)
- 2013年8月(1)
- 2013年7月(3)
- 2013年6月(2)
- 2013年5月(1)
- 2013年4月(3)
- 2013年3月(1)
- 2013年2月(2)
- 2013年1月(2)
- 2012年12月(11)
- 2012年11月(12)
- 2012年10月(12)
- 2012年9月(26)
- 2012年8月(29)
- 2012年7月(18)
- 2012年6月(2)
- 2012年5月(25)
- 2012年4月(16)
- 2012年3月(13)
- 2012年2月(6)
标签
blogger

